Apache Hadoop es una solución de big data para almacenar y analizar grandes cantidades de datos. En este artículo, detallaremos los complejos pasos de configuración de Apache Hadoop para que pueda comenzar a usarlo en Ubuntu lo más rápido posible. En esta publicación, instalaremos Apache Hadoop en Ubuntu 17.10 máquina.
Versión de Ubuntu
Para esta guía, usaremos la versión 17 de Ubuntu.10 (GNU / Linux 4.13.0-38-genérico x86_64).
Actualizar paquetes existentes
Para iniciar la instalación de Hadoop, es necesario que actualicemos nuestra máquina con los últimos paquetes de software disponibles. Podemos hacer esto con:
sudo apt-get update && sudo apt-get -y dist-upgradeComo Hadoop está basado en Java, necesitamos instalarlo en nuestra máquina. Podemos usar cualquier versión de Java por encima de Java 6. Aquí, usaremos Java 8:
sudo apt-get -y instalar openjdk-8-jdk-headlessDescarga de archivos Hadoop
Todos los paquetes necesarios ahora existen en nuestra máquina. Estamos listos para descargar los archivos TAR de Hadoop necesarios para que podamos comenzar a configurarlos y ejecutar un programa de muestra con Hadoop también.
En esta guía, instalaremos Hadoop v3.0.1. Descarga los archivos correspondientes con este comando:
wget http: // espejo.cc.Columbia.edu / pub / software / apache / hadoop / common / hadoop-3.0.1 / hadoop-3.0.1.alquitrán.gzDependiendo de la velocidad de la red, esto puede tardar unos minutos ya que el archivo es de gran tamaño:
Descargando Hadoop
Encuentre los últimos binarios de Hadoop aquí. Ahora que tenemos el archivo TAR descargado, podemos extraerlo en el directorio actual:
alquitrán xvzf hadoop-3.0.1.alquitrán.gzEsto tardará unos segundos en completarse debido al gran tamaño de archivo del archivo:
Hadoop sin archivar
Se agregó un nuevo grupo de usuarios de Hadoop
Como Hadoop opera sobre HDFS, un nuevo sistema de archivos también puede alterar nuestro propio sistema de archivos en la máquina Ubuntu. Para evitar esta colisión, crearemos un grupo de usuarios completamente separado y lo asignaremos a Hadoop para que contenga sus propios permisos. Podemos agregar un nuevo grupo de usuarios con este comando:
addgroup hadoopVeremos algo como:
Agregar un grupo de usuarios de Hadoop
Estamos listos para agregar un nuevo usuario a este grupo:
useradd -G hadoop hadoopuserTenga en cuenta que todos los comandos que ejecutamos son como usuario root. Con el comando aove, pudimos agregar un nuevo usuario al grupo que creamos.
Para permitir que el usuario de Hadoop realice operaciones, también debemos proporcionarle acceso de root. Abre el / etc / sudoers archivo con este comando:
sudo visudoAntes de agregar algo, el archivo se verá así:
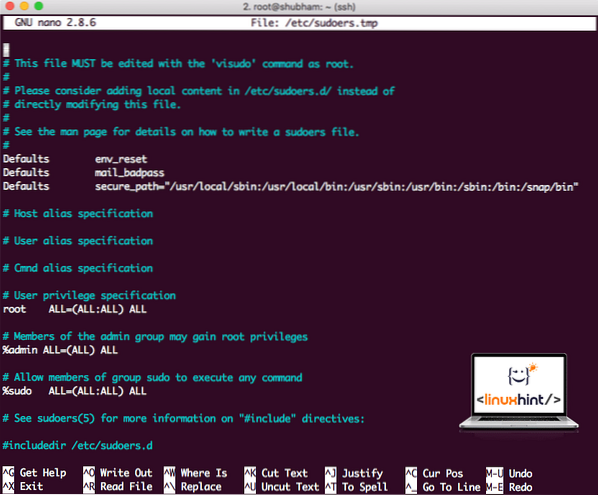
Archivo Sudoers antes de agregar nada
Agregue la siguiente línea al final del archivo:
hadoopuser TODOS = (TODOS) TODOSAhora el archivo se verá así:
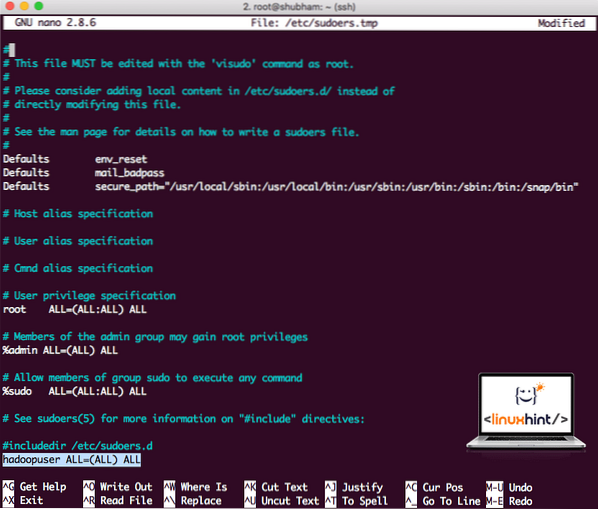
Archivo Sudoers después de agregar un usuario de Hadoop
Esta fue la configuración principal para proporcionar a Hadoop una plataforma para realizar acciones. Estamos listos para configurar un clúster Hadoop de un solo nodo ahora.
Configuración de nodo único de Hadoop: modo independiente
Cuando se trata del poder real de Hadoop, generalmente se configura en varios servidores para que pueda escalar sobre una gran cantidad de conjuntos de datos presentes en Sistema de archivos distribuido Hadoop (HDFS). Esto generalmente está bien con entornos de depuración y no se usa para uso de producción. Para mantener el proceso simple, explicaremos cómo podemos hacer una configuración de nodo único para Hadoop aquí.
Una vez que hayamos terminado de instalar Hadoop, también ejecutaremos una aplicación de muestra en Hadoop. A partir de ahora, el archivo Hadoop se denomina hadoop-3.0.1. cambiemos el nombre a hadoop para un uso más simple:
mv hadoop-3.0.1 hadoopEl archivo ahora se ve así:
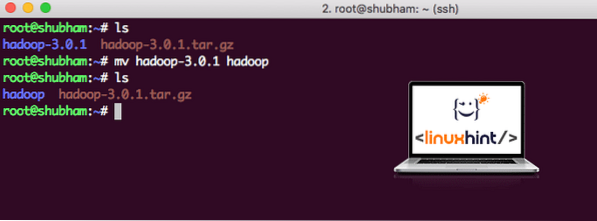
Mover Hadoop
Es hora de hacer uso del usuario hadoop que creamos anteriormente y asignar la propiedad de este archivo a ese usuario:
chown -R hadoopuser: hadoop / root / hadoopUna mejor ubicación para Hadoop será el directorio / usr / local /, así que vamos a moverlo allí:
mv hadoop / usr / local /cd / usr / local /
Agregar Hadoop a la ruta
Para ejecutar scripts de Hadoop, lo agregaremos a la ruta ahora. Para hacer esto, abra el archivo bashrc:
vi ~ /.bashrcAgregue estas líneas al final del .bashrc para que la ruta pueda contener la ruta del archivo ejecutable de Hadoop:
# Configurar Hadoop y Java Homeexportar HADOOP_HOME = / usr / local / hadoop
exportar JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64
export PATH = $ PATH: $ HADOOP_HOME / bin
El archivo se parece a:
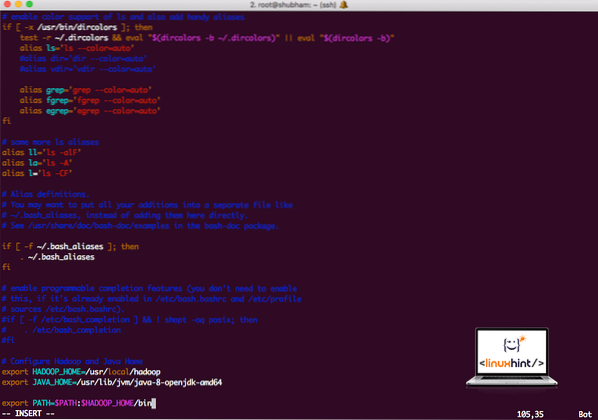
Agregar Hadoop a la ruta
Como Hadoop hace uso de Java, debemos indicarle al archivo de entorno de Hadoop hadoop-env.sh donde esta ubicado. La ubicación de este archivo puede variar según las versiones de Hadoop. Para encontrar fácilmente dónde se encuentra este archivo, ejecute el siguiente comando justo fuera del directorio de Hadoop:
encontrar hadoop / -name hadoop-env.shObtendremos la salida para la ubicación del archivo:
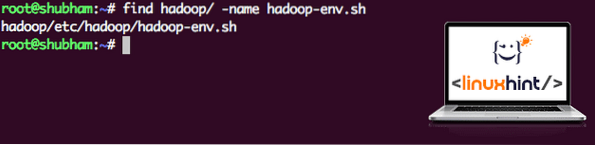
Ubicación del archivo de entorno
Editemos este archivo para informar a Hadoop sobre la ubicación del JDK de Java e inserte esto en la última línea del archivo y guárdelo:
exportar JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64La instalación y configuración de Hadoop ahora está completa. Estamos listos para ejecutar nuestra aplicación de muestra ahora. Pero espere, nunca hicimos una aplicación de muestra!
Ejecución de la aplicación de muestra con Hadoop
En realidad, la instalación de Hadoop viene con una aplicación de muestra incorporada que está lista para ejecutarse una vez que hayamos terminado con la instalación de Hadoop. Suena bien, verdad?
Ejecute el siguiente comando para ejecutar el ejemplo de JAR:
hadoop jar / root / hadoop / share / hadoop / mapreduce / hadoop-mapreduce-examples-3.0.1.jar wordcount / root / hadoop / README.txt / root / SalidaHadoop mostrará cuánto procesamiento hizo en el nodo:
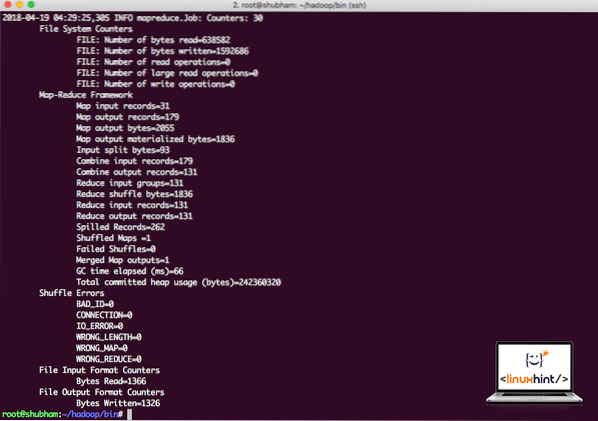
Estadísticas de procesamiento de Hadoop
Una vez que ejecuta el siguiente comando, vemos el archivo part-r-00000 como salida. Continúe y observe el contenido de la salida:
gato parte-r-00000Obtendrá algo como:
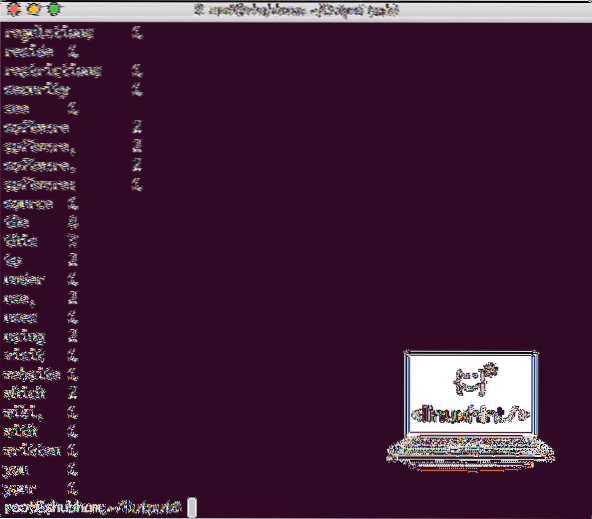
Salida de recuento de palabras de Hadoop
Conclusión
En esta lección, vimos cómo podemos instalar y comenzar a usar Apache Hadoop en Ubuntu 17.10 máquina. Hadoop es excelente para almacenar y analizar una gran cantidad de datos y espero que este artículo lo ayude a comenzar a usarlo en Ubuntu rápidamente.


