En esta lección, eso es lo que pretendemos hacer. Descubriremos cómo se pueden extraer los valores de diferentes etiquetas HTML y también anularemos la funcionalidad predeterminada de este módulo para agregar algo de lógica propia. Haremos esto usando el HTMLParser clase en Python en html.analizador módulo. Veamos el código en acción.
Mirando la clase HTMLParser
Para analizar texto HTML en Python, podemos hacer uso de HTMLParser clase en html.analizador módulo. Veamos la definición de clase para el HTMLParser clase:
clase html.analizador.HTMLParser (*, convert_charrefs = True)La convert_charrefs campo, si se establece en True hará que todas las referencias de caracteres se conviertan a sus equivalentes Unicode. Solo el guión / estilo los elementos no se convierten. Ahora, intentaremos comprender cada función de esta clase para comprender mejor lo que hace cada función.
- handle_startendtag Esta es la primera función que se activa cuando se pasa una cadena HTML a la instancia de la clase. Una vez que el texto llega aquí, el control se pasa a otras funciones en la clase que se reduce a otras etiquetas en el String. Esto también está claro en la definición de esta función: def handle_startendtag (self, tag, attrs):
uno mismo.handle_starttag (etiqueta, atributos)
uno mismo.handle_endtag (etiqueta) - handle_starttag: Este método gestiona la etiqueta de inicio de los datos que recibe. Su definición es la que se muestra a continuación: def handle_starttag (self, tag, attrs):
aprobar - handle_endtag: Este método administra la etiqueta final para los datos que recibe: def handle_endtag (self, tag):
aprobar - handle_charref: Este método gestiona las referencias de caracteres en los datos que recibe. Su definición es la que se muestra a continuación: def handle_charref (self, name):
aprobar - handle_entityref: Esta función maneja las referencias de entidad en el HTML que se le pasa: def handle_entityref (self, name):
aprobar - handle_data: Esta es la función donde se realiza un trabajo real para extraer valores de las etiquetas HTML y se pasan los datos relacionados con cada etiqueta. Su definición es la que se muestra a continuación: def handle_data (self, data):
aprobar - handle_comment: Usando esta función, también podemos obtener comentarios adjuntos a una fuente HTML: def handle_comment (self, data):
aprobar - handle_pi: Como HTML también puede tener instrucciones de procesamiento, esta es la función donde estas Su definición es como se muestra a continuación: def handle_pi (self, data):
aprobar - handle_decl: Este método maneja las declaraciones en el HTML, su definición se proporciona como: def handle_decl (self, decl):
aprobar
Subclasificación de la clase HTMLParser
En esta sección, subclasificaremos la clase HTMLParser y veremos algunas de las funciones que se llaman cuando los datos HTML se pasan a la instancia de la clase. Escribamos un script simple que haga todo esto:
desde html.parser importar HTMLParserclase LinuxHTMLParser (HTMLParser):
def handle_starttag (self, tag, attrs):
print ("Etiqueta de inicio encontrada:", etiqueta)
def handle_endtag (self, tag):
print ("Etiqueta final encontrada:", etiqueta)
def handle_data (self, data):
imprimir ("Datos encontrados:", datos)
analizador = LinuxHTMLParser ()
analizador.alimentación("
'
Módulo de análisis de HTML de Python
')
Esto es lo que obtenemos con este comando:
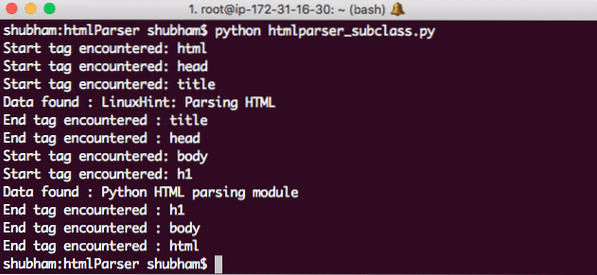
Subclase Python HTMLParser
Funciones HTMLParser
En esta sección, trabajaremos con varias funciones de la clase HTMLParser y veremos la funcionalidad de cada una de ellas:
desde html.parser importar HTMLParserdesde html.entidades importan name2codepoint
clase LinuxHint_Parse (HTMLParser):
def handle_starttag (self, tag, attrs):
print ("Etiqueta de inicio:", etiqueta)
para attr en attrs:
print ("attr:", attr)
def handle_endtag (self, tag):
print ("Etiqueta final:", etiqueta)
def handle_data (self, data):
imprimir ("Datos:", datos)
def handle_comment (self, data):
imprimir ("Comentario:", datos)
def handle_entityref (self, name):
c = chr (name2codepoint [nombre])
print ("Nombrado ent:", c)
def handle_charref (self, name):
si nombre.empieza con ('x'):
c = chr (int (nombre [1:], 16))
demás:
c = chr (int (nombre))
print ("Num ent:", c)
def handle_decl (self, data):
imprimir ("Decl:", datos)
analizador = LinuxHint_Parse ()
Con varias llamadas, alimentemos datos HTML separados a esta instancia y veamos qué resultado generan estas llamadas. Empezaremos con un simple DOCTYPE cuerda:
analizador.alimentación(''"http: // www.w3.org / TR / html4 / estricto.dtd "> ')Esto es lo que obtenemos con esta llamada:
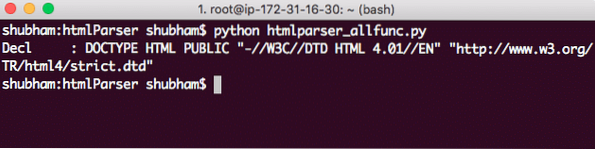
Cadena DOCTYPE
Probemos ahora con una etiqueta de imagen y veamos qué datos extrae:
analizador.alimentación(' ')
') Esto es lo que obtenemos con esta llamada:

Etiqueta de imagen HTMLParser
A continuación, probemos cómo se comporta la etiqueta de secuencia de comandos con las funciones de Python:
analizador.alimentación('')analizador.alimentación('')
analizador.feed ('# python color: green')
Esto es lo que obtenemos con esta llamada:

Etiqueta de secuencia de comandos en htmlparser
Finalmente, también pasamos comentarios a la sección HTMLParser:
analizador.alimentación('''')
Esto es lo que obtenemos con esta llamada:

Analizando comentarios
Conclusión
En esta lección, vimos cómo podemos analizar HTML usando la propia clase HTMLParser de Python sin ninguna otra biblioteca. Podemos modificar fácilmente el código para cambiar la fuente de los datos HTML a un cliente HTTP.
Lea más publicaciones basadas en Python aquí.


