La World Wide Web es la fuente completa y definitiva de todos los datos que existen. El rápido desarrollo que ha experimentado Internet en las últimas tres décadas no ha tenido precedentes. Como resultado, la web se está montando con cientos de terabytes de datos todos los días.
Todos estos datos tienen algún valor para cierta persona. Por ejemplo, su historial de navegación tiene importancia para las aplicaciones de redes sociales, ya que lo utilizan para personalizar los anuncios que le muestran. Y también hay mucha competencia por estos datos; unos pocos MB más de algunos datos pueden dar a las empresas una ventaja sustancial sobre la competencia.
Minería de datos con Python
Para ayudar a aquellos de ustedes que son nuevos en la extracción de datos, hemos preparado esta guía en la que mostraremos cómo extraer datos de la web utilizando Python y la biblioteca Beautiful soup.
Suponemos que ya tiene un nivel intermedio de familiaridad con Python y HTML, ya que trabajará con ambos siguiendo las instrucciones de esta guía.
Tenga cuidado con los sitios en los que está probando sus nuevas habilidades de minería de datos, ya que muchos sitios consideran esto intrusivo y saben que podría haber repercusiones.
Instalación y preparación de bibliotecas
Ahora, vamos a usar dos bibliotecas que vamos a usar: la biblioteca de solicitud de Python para cargar contenido fuera de las páginas web y la biblioteca Beautiful Soup para el fragmento real del proceso. Hay alternativas a BeautifulSoup, eso sí, y si está familiarizado con alguno de los siguientes, siéntase libre de usar estos en su lugar: Scrappy, Mechanize, Selenium, Portia, kimono y ParseHub.
La biblioteca de solicitudes se puede descargar e instalar con el comando pip como en:
# solicitudes de instalación pip3
La biblioteca de solicitudes debe estar instalada en su dispositivo. Del mismo modo, descargue BeautifulSoup también:
# pip3 instalar beautifulsoup4
Con eso, nuestras bibliotecas están listas para la acción.
Como se mencionó anteriormente, la biblioteca de solicitudes no tiene mucho uso más que recuperar el contenido de las páginas web. La biblioteca de BeautifulSoup y las bibliotecas de solicitudes tienen un lugar en cada script que va a escribir, y deben importarse antes de cada uno de la siguiente manera:
$ solicitudes de importación$ de bs4 importar BeautifulSoup como bs
Esto agrega la palabra clave solicitada al espacio de nombres, indicando a Python el significado de la palabra clave cada vez que se solicita su uso. Lo mismo sucede con la palabra clave bs, aunque aquí tenemos la ventaja de asignar una palabra clave más simple para BeautifulSoup.
página web = solicitudes.obtener (URL)El código anterior obtiene la URL de la página web y crea una cadena directa a partir de ella, almacenándola en una variable.
$ webcontent = página web.contenidoEl comando anterior copia el contenido de la página web y lo asigna al contenido web variable.
Con eso, hemos terminado con la biblioteca de solicitudes. Todo lo que queda por hacer es cambiar las opciones de la biblioteca de solicitudes a las opciones de BeautifulSoup.
$ htmlcontent = bs (contenido web, "html.analizador ")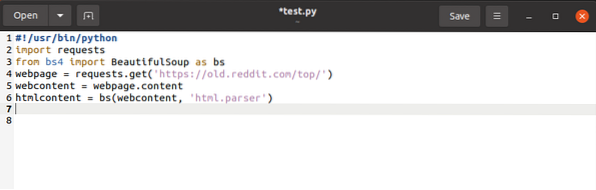
Esto analiza el objeto de solicitud y lo convierte en objetos HTML legibles.
Con todo eso resuelto, podemos pasar al bit de raspado real.
Web scraping con Python y BeautifulSoup
Sigamos adelante y veamos cómo podemos extraer objetos HTML de datos con BeautifulSoup.
Para ilustrar un ejemplo, mientras explicamos las cosas, trabajaremos con este fragmento html:
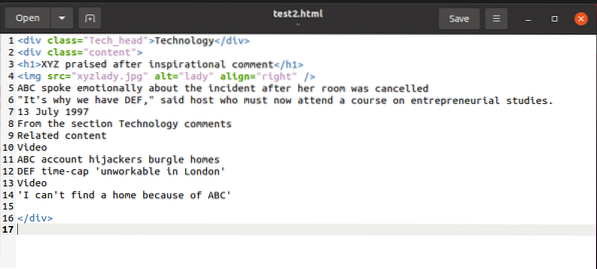
Podemos acceder al contenido de este fragmento con BeautifulSoup y usarlo en la variable de contenido HTML como en:
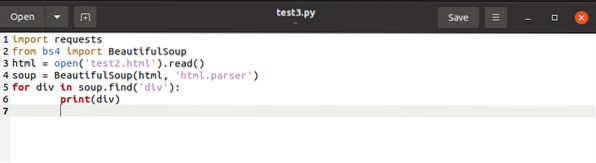
El código de arriba busca cualquier etiqueta nombrada
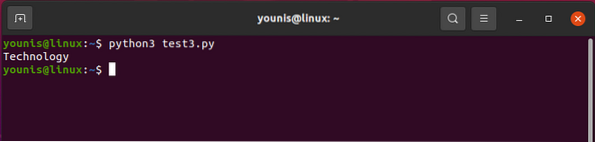
Para guardar simultáneamente las etiquetas nombradas
a una lista, emitiríamos el código final como se indica a continuación: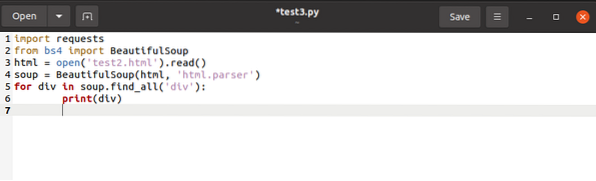
La salida debería volver así:
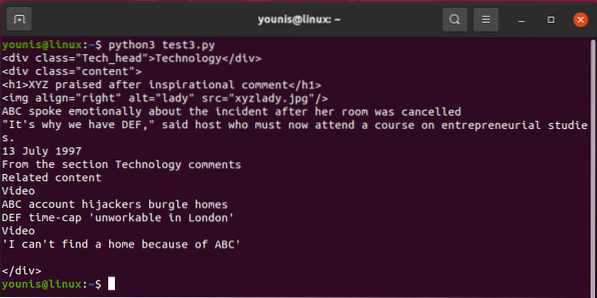
Para convocar a uno de los
Ahora veamos cómo elegir
etiquetas manteniendo en perspectiva sus características. Para separar un , necesitaríamos el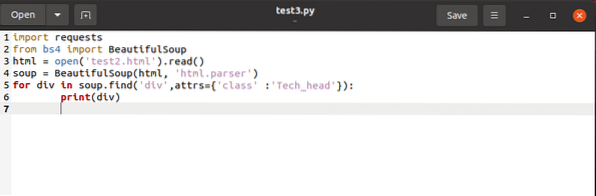
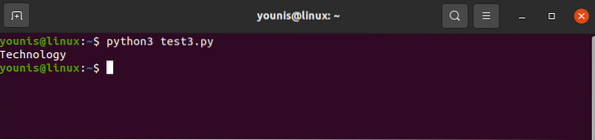
para div en sopa.find_all ('div', attrs = 'class' = 'Tech_head'):
Esto trae el
etiqueta.Obtendrías:
Tecnología
Todo sin etiquetas.
Por último, cubriremos cómo seleccionar el valor del atributo en una etiqueta. El código debe tener esta etiqueta:
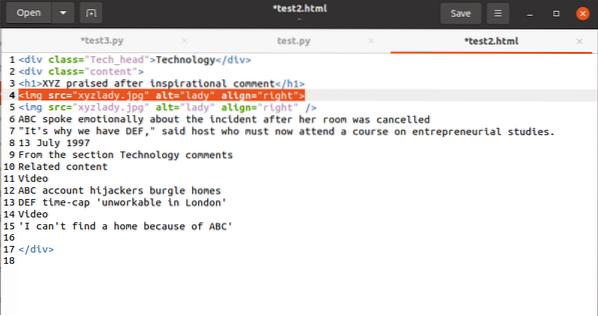

Para operar el valor asociado con el atributo src, usaría lo siguiente:
contenido html.buscar ("img") ["src"]Y la salida resultaría como:
"images_4 / una-guía-para-principiantes-para-raspar-web-con-python-y-una-sopa-hermosa.jpg "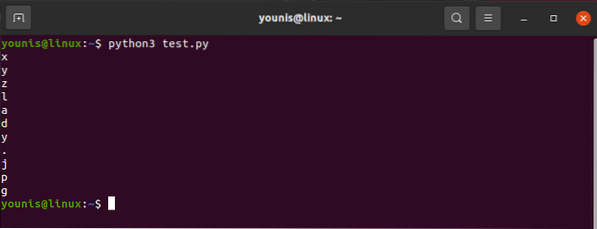
Oh chico, seguro que es mucho trabajo!
Si siente que su familiaridad con Python o HTML es inadecuada o si simplemente está abrumado con el web scraping, no se preocupe.
Si usted es una empresa que necesita adquirir un tipo particular de datos con regularidad, pero no puede hacer el web-scraping usted mismo, hay formas de solucionar este problema. Pero debes saber que te va a costar algo de dinero. Puede encontrar a alguien que lo haga por usted, o puede obtener el servicio de datos premium de sitios web como Google y Twitter para compartir los datos con usted. Estos comparten partes de sus datos mediante el empleo de API, pero estas llamadas a API son limitadas por día. Aparte de eso, sitios web como estos pueden ser muy protectores de sus datos. Por lo general, muchos de estos sitios no comparten ninguno de sus datos.
Pensamientos finales
Antes de terminar, déjeme decirle en voz alta si no ha sido ya evidente; los comandos find (), find_all () son tus mejores amigos cuando estás raspando con BeautifulSoup. Aunque hay mucho más que cubrir para el raspado de datos maestros con Python, esta guía debería ser suficiente para aquellos de ustedes que recién comienzan.


