Apache Kafka
Para una definición de alto nivel, presentemos una breve definición de Apache Kafka:
Apache Kafka es un registro de confirmación distribuido, tolerante a fallos y escalable horizontalmente.
Esas fueron algunas palabras de alto nivel sobre Apache Kafka. Entendamos los conceptos en detalle aquí.
- Repartido: Kafka divide los datos que contiene en varios servidores y cada uno de estos servidores es capaz de manejar las solicitudes de los clientes para compartir los datos que contiene
- Tolerante a fallos: Kafka no tiene un solo punto de falla. En un sistema SPoF, como una base de datos MySQL, si el servidor que aloja la base de datos deja de funcionar, la aplicación se estropea. En un sistema que no tiene un SPoF y consta de múltiples nodos, incluso si la mayor parte del sistema falla, sigue siendo el mismo para un usuario final.
- Escalable horizontalmente: Este tipo de escalado se refiere a agregar más máquinas al clúster existente. Esto significa que Apache Kafka es capaz de aceptar más nodos en su clúster y no proporcionar tiempo de inactividad para las actualizaciones necesarias del sistema. Mire la imagen a continuación para comprender el tipo de conceptos de escalado:
- Confirmar registro: Un registro de confirmación es una estructura de datos como una lista vinculada. Agrega los mensajes que le llegan y siempre mantiene su orden. Los datos no se pueden eliminar de este registro hasta que se alcance un tiempo especificado para esos datos.
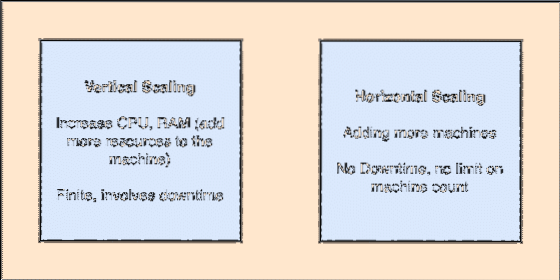
Escalado vertical y horizontal
Un tema en Apache Kafka es como una cola donde se almacenan los mensajes. Estos mensajes se almacenan durante un período de tiempo configurable y el mensaje no se elimina hasta que se alcanza este tiempo, incluso si ha sido consumido por todos los consumidores conocidos.
Kafka es escalable, ya que son los consumidores quienes realmente almacenan el último mensaje que obtuvieron como un valor de "compensación". Veamos una figura para entender esto mejor: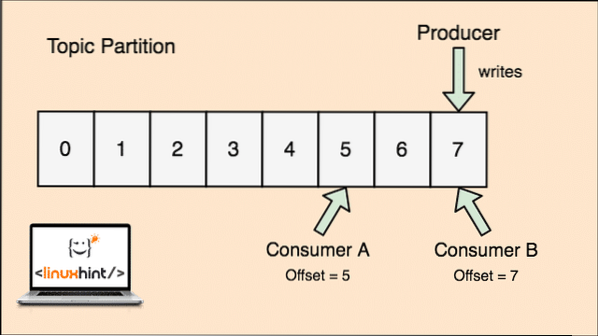
Partición de tema y compensación de consumidor en Apache Kafka
Introducción a Apache Kafka
Para comenzar a usar Apache Kafka, debe estar instalado en la máquina. Para hacer esto, lea Instalar Apache Kafka en Ubuntu.
Asegúrese de tener una instalación activa de Kafka si desea probar los ejemplos que presentamos más adelante en la lección.
Como funciona?
Con Kafka, el Productor las aplicaciones publican mensajes que llega a un Kafka Nodo y no directamente a un consumidor. Desde este nodo de Kafka, los mensajes son consumidos por el Consumidor aplicaciones.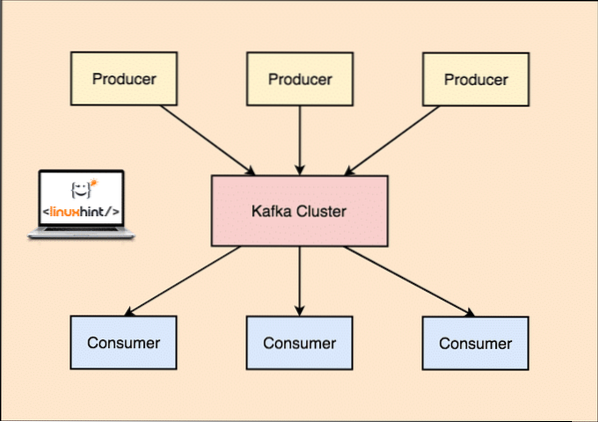
Productor y consumidor de Kafka
Como un solo tema puede obtener una gran cantidad de datos de una sola vez, para mantener Kafka escalable horizontalmente, cada tema se divide en particiones y cada partición puede vivir en cualquier máquina nodo de un clúster. Intentemos presentarlo:
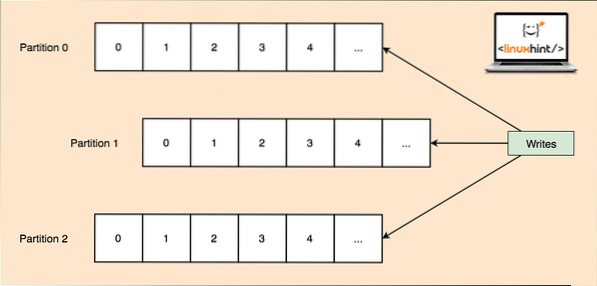
Particiones de tema
Nuevamente, Kafka Broker no lleva un registro de qué consumidor ha consumido cuántos paquetes de datos. Es el responsabilidad de los consumidores de realizar un seguimiento de los datos que ha consumido.
Persistencia en disco
Kafka conserva los registros de mensajes que recibe de los productores en el disco y no los guarda en la memoria. Una pregunta que podría surgir es cómo esto hace que las cosas sean factibles y rápidas? Hubo varias razones detrás de esto, lo que lo convierte en una forma óptima de administrar los registros de mensajes:
- Kafka sigue un protocolo de agrupación de registros de mensajes. Los productores producen mensajes que se conservan en el disco en grandes porciones y los consumidores también consumen estos registros de mensajes en grandes porciones lineales.
- La razón por la que las escrituras en disco son lineales es que esto hace que las lecturas sean más rápidas debido a que el tiempo de lectura del disco lineal es muy reducido.
- Las operaciones de disco lineal se optimizan mediante Sistemas operativos también mediante el uso de técnicas de escribir detrás y leer por adelantado.
- Los sistemas operativos modernos también utilizan el concepto de Almacenamiento en caché lo que significa que almacenan en caché algunos datos del disco en la RAM libre disponible.
- Dado que Kafka conserva los datos en datos estándar uniformes en todo el flujo desde el productor hasta el consumidor, hace uso de la optimización de copia cero proceso.
Distribución y replicación de datos
Como estudiamos anteriormente, un tema se divide en particiones, cada registro de mensaje se replica en varios nodos del clúster para mantener el orden y los datos de cada registro en caso de que uno de los nodos muera.
Aunque una partición se replica en varios nodos, todavía hay una líder de partición nodo a través del cual las aplicaciones leen y escriben datos sobre el tema y el líder replica datos en otros nodos, que se denominan como seguidores de esa partición.
Si los datos del registro de mensajes son muy importantes para una aplicación, la garantía de que el registro de mensajes está seguro en uno de los nodos se puede aumentar aumentando la factor de replicación del Cluster.
Que es Zookeeper?
Zookeeper es un almacén de valor-clave distribuido y altamente tolerante a fallos. Apache Kafka depende en gran medida de Zookeeper para almacenar la mecánica del clúster como el latido del corazón, distribuir actualizaciones / configuraciones, etc.).
Permite a los corredores de Kafka suscribirse a sí mismos y saber cuándo se ha producido algún cambio con respecto al líder de una partición y la distribución de los nodos.
Las aplicaciones para productores y consumidores se comunican directamente con Zookeeper aplicación para saber qué nodo es el líder de partición para un tema para que puedan realizar lecturas y escrituras desde el líder de partición.
Transmisión
Un procesador de flujo es un componente principal en un clúster de Kafka que toma un flujo continuo de datos de registros de mensajes de los temas de entrada, procesa estos datos y crea un flujo de datos para los temas de salida que pueden ser cualquier cosa, desde la basura hasta una base de datos.
Es completamente posible realizar un procesamiento simple directamente usando las API de productor / consumidor, aunque para el procesamiento complejo como combinar flujos, Kafka proporciona una biblioteca API de Streams integrada, pero tenga en cuenta que esta API está destinada a ser utilizada dentro de nuestra propia base de código y no lo hace. ejecutar en un corredor. Funciona de manera similar a la API del consumidor y nos ayuda a escalar el trabajo de procesamiento de transmisión en múltiples aplicaciones.
Cuándo usar Apache Kafka?
Como estudiamos en las secciones anteriores, Apache Kafka se puede utilizar para tratar una gran cantidad de registros de mensajes que pueden pertenecer a una cantidad prácticamente infinita de temas en nuestros sistemas.
Apache Kafka es un candidato ideal cuando se trata de usar un servicio que puede permitirnos seguir la arquitectura impulsada por eventos en nuestras aplicaciones. Esto se debe a sus capacidades de persistencia de datos, arquitectura tolerante a fallas y altamente distribuida donde las aplicaciones críticas pueden confiar en su desempeño.
La arquitectura escalable y distribuida de Kafka hace que la integración con microservicios sea muy fácil y permite que una aplicación se desacople con mucha lógica empresarial.
Crear un tema nuevo
Podemos crear un tema de prueba pruebas en el servidor Apache Kafka con el siguiente comando:
Creando un tema
sudo kafka-temas.sh --create --zookeeper localhost: 2181 - factor de replicación 1--particiones 1 - prueba de tema
Esto es lo que obtenemos con este comando: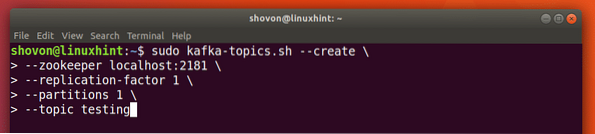
Crear nuevo tema de Kafka
Se creará un tema de prueba que podemos confirmar con el comando mencionado:
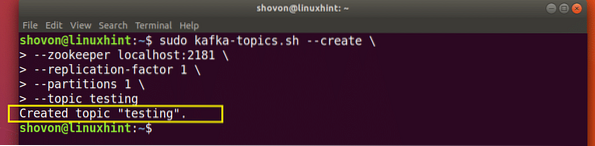
Confirmación de creación de tema de Kafka
Escribir mensajes sobre un tema
Como estudiamos anteriormente, una de las API presentes en Apache Kafka es la API de productor. Usaremos esta API para crear un nuevo mensaje y publicarlo en el tema que acabamos de crear:
Escribir mensaje al tema
sudo kafka-consola-productor.sh --broker-list localhost: 9092 --prueba de temaVeamos el resultado de este comando:
Publicar mensaje en Kafka Topic
Una vez que presionemos la tecla, veremos un nuevo signo de flecha (>) que significa que ahora podemos ingresar datos:

Escribir un mensaje
Simplemente escriba algo y presione para comenzar una nueva línea. Escribí 3 líneas de textos:
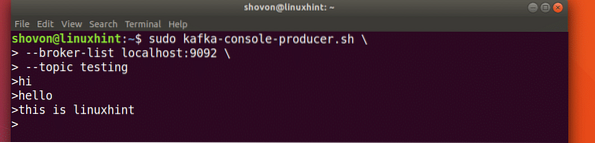
Leer mensajes del tema
Ahora que hemos publicado un mensaje sobre el tema de Kafka que creamos, este mensaje estará allí durante un tiempo configurable. Podemos leerlo ahora usando el API de consumidor:
Leer mensajes del tema
sudo kafka-consola-consumidor.sh --zookeeper localhost: 2181 --prueba de tema: desde el principio
Esto es lo que obtenemos con este comando:
Comando para leer el mensaje del tema de Kafka
Podremos ver los mensajes o líneas que hemos escrito usando la API de Producer como se muestra a continuación:
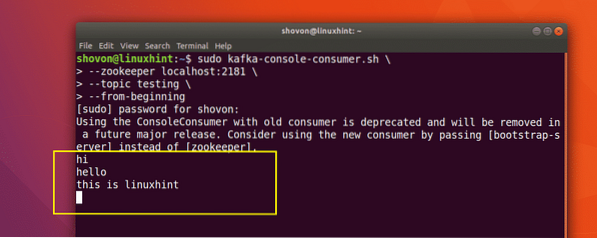
Si escribimos otro mensaje nuevo usando la API del productor, también se mostrará instantáneamente en el lado del consumidor:
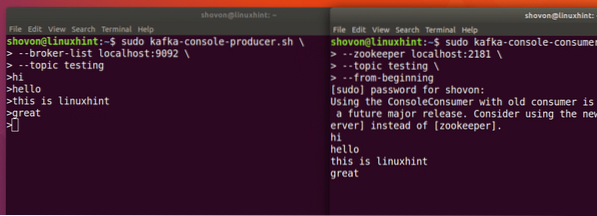
Publicar y consumir al mismo tiempo
Conclusión
En esta lección, analizamos cómo comenzamos a usar Apache Kafka, que es un excelente Message Broker y también puede actuar como una unidad especial de persistencia de datos.


