Esa descripción general es un poco abstracta, así que vamos a basarla en un escenario del mundo real, imagine que necesita monitorear varios servidores web. Cada uno tiene su propio sitio web, y constantemente se generan nuevos registros en cada uno de ellos cada segundo del día. Además de eso, hay una serie de servidores de correo electrónico que también debe controlar.
Es posible que deba almacenar esos datos para fines de facturación y mantenimiento de registros, que es un trabajo por lotes que no requiere atención inmediata. Es posible que desee ejecutar análisis de los datos para tomar decisiones en tiempo real, lo que requiere una entrada de datos precisa e inmediata. De repente, se encuentra en la necesidad de optimizar los datos de una manera sensata para todas las diversas necesidades. Kafka actúa como esa capa de abstracción en la que múltiples fuentes pueden publicar diferentes flujos de datos y un determinado consumidor puede suscribirse a las transmisiones que considere relevantes. Kafka se asegurará de que los datos estén bien ordenados. Son los aspectos internos de Kafka los que debemos comprender antes de pasar al tema de particiones y claves.
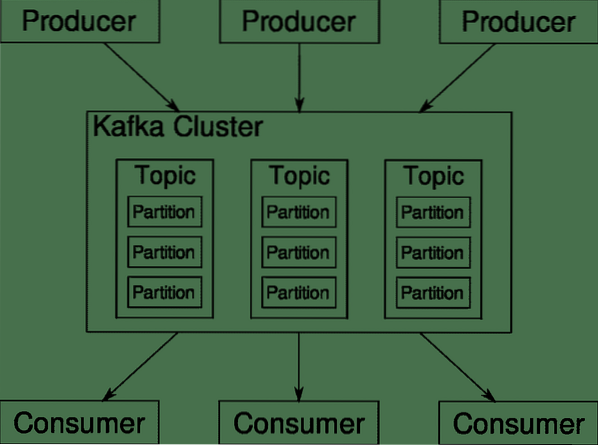
Temas, broker y particiones de Kafka
Kafka Temas son como tablas de una base de datos. Cada tema consta de datos de una fuente particular de un tipo particular. Por ejemplo, el estado de su clúster puede ser un tema que consta de información sobre el uso de la CPU y la memoria. De manera similar, el tráfico entrante a través del clúster puede ser otro tema.
Kafka está diseñado para ser escalable horizontalmente. Es decir, una sola instancia de Kafka consta de múltiples Kafka corredores corriendo a través de múltiples nodos, cada uno puede manejar flujos de datos paralelos al otro. Incluso si algunos de los nodos fallan, su canalización de datos puede seguir funcionando. Un tema en particular se puede dividir en una serie de particiones. Esta partición es uno de los factores cruciales detrás de la escalabilidad horizontal de Kafka.
Múltiple productores, fuentes de datos para un tema dado, pueden escribir en ese tema simultáneamente porque cada uno escribe en una partición diferente, en cualquier punto dado. Ahora, por lo general, los datos se asignan a una partición de forma aleatoria, a menos que le proporcionemos una clave.
Partición y ordenación
Solo para recapitular, los productores escriben datos sobre un tema determinado. Ese tema en realidad está dividido en múltiples particiones. Y cada partición vive independientemente de las demás, incluso para un tema determinado. Esto puede generar mucha confusión cuando el orden de los datos es importante. Tal vez necesite sus datos en orden cronológico, pero tener múltiples particiones para su flujo de datos no garantiza un orden perfecto.
Puede usar una sola partición por tema, pero eso anula todo el propósito de la arquitectura distribuida de Kafka. Entonces necesitamos alguna otra solución.
Claves para particiones
Los datos de un productor se envían a particiones de forma aleatoria, como mencionamos antes. Los mensajes son los fragmentos reales de datos. Lo que los productores pueden hacer además de enviar mensajes es agregar una clave que lo acompañe.
Todos los mensajes que vienen con la clave específica irán a la misma partición. Entonces, por ejemplo, la actividad de un usuario se puede rastrear cronológicamente si los datos de ese usuario están etiquetados con una clave y, por lo tanto, siempre terminan en una partición. Llamemos a esta partición p0 y al usuario u0.
La partición p0 siempre recogerá los mensajes relacionados con u0 porque esa clave los une. Pero eso no significa que p0 solo esté relacionado con eso. También puede aceptar mensajes de u1 y u2 si tiene la capacidad para hacerlo. Del mismo modo, otras particiones pueden consumir datos de otros usuarios.
El punto de que los datos de un usuario determinado no se distribuyen en diferentes particiones, lo que garantiza el orden cronológico para ese usuario. Sin embargo, el tema general de datos del usuario, todavía puede aprovechar la arquitectura distribuida de Apache Kafka.
Conclusión
Mientras que los sistemas distribuidos como Kafka resuelven algunos problemas antiguos como la falta de escalabilidad o tener un solo punto de falla. Vienen con una serie de problemas que son exclusivos de su propio diseño. Anticipar estos problemas es un trabajo esencial de cualquier arquitecto de sistemas. No solo eso, a veces realmente tienes que hacer un análisis de costo-beneficio para determinar si los nuevos problemas son una compensación digna para deshacerse de los más antiguos. Los pedidos y la sincronización son solo la punta del iceberg.
Con suerte, artículos como estos y la documentación oficial pueden ayudarlo en el camino.


