TensorFlow ha encontrado un uso inmenso en el campo del aprendizaje automático, precisamente porque el aprendizaje automático implica una gran cantidad de procesamiento numérico y se utiliza como una técnica generalizada de resolución de problemas. Y aunque interactuaremos con él usando Python, tiene interfaces para otros lenguajes como Go, Node.js e incluso C #.
Tensorflow es como una caja negra que esconde todas las sutilezas matemáticas en su interior y el desarrollador simplemente llama a las funciones correctas para resolver un problema. Pero que problema?
Aprendizaje automático (ML)
Suponga que está diseñando un bot para jugar una partida de ajedrez. Debido a la forma en que se diseña el ajedrez, la forma en que se mueven las piezas y el objetivo bien definido del juego, es muy posible escribir un programa que juegue extremadamente bien. De hecho, superaría a toda la raza humana en el ajedrez. Sabría exactamente qué movimiento necesita hacer dado el estado de todas las piezas en el tablero.
Sin embargo, tal programa solo puede jugar al ajedrez. Las reglas del juego están integradas en la lógica del código y todo lo que hace ese programa es ejecutar esa lógica de manera rigurosa y más precisa de lo que cualquier humano podría hacerlo. No es un algoritmo de propósito general que puedas usar para diseñar cualquier bot de juego.
Con el aprendizaje automático, el paradigma cambia y los algoritmos se vuelven cada vez más de uso general.
La idea es simple, comienza definiendo un problema de clasificación. Por ejemplo, desea automatizar el proceso de identificación de especies de arañas. Las especies que conoce son las diversas clases (que no deben confundirse con las clases taxonómicas) y el objetivo del algoritmo es clasificar una nueva imagen desconocida en una de estas clases.
Aquí, el primer paso para el ser humano sería determinar las características de varias arañas individuales. Proporcionaríamos datos sobre la longitud, el ancho, la masa corporal y el color de las arañas individuales junto con las especies a las que pertenecen:
| Largo | Ancho | Masa | Color | Textura | Especies |
| 5 | 3 | 12 | marrón | liso | Papá piernas largas |
| 10 | 8 | 28 | Marrón-negro | peludo | Tarántula |
Tener una gran colección de estos datos de araña individuales se utilizará para 'entrenar' el algoritmo y se usará otro conjunto de datos similar para probar el algoritmo y ver qué tan bien funciona contra nueva información que nunca antes había encontrado, pero que ya conocemos. Respuesta para.
El algoritmo comenzará de forma aleatoria. Es decir, toda araña independientemente de sus características sería clasificada como cualquiera de la especie. Si hay 10 especies diferentes en nuestro conjunto de datos, entonces este algoritmo ingenuo recibiría la clasificación correcta aproximadamente una décima parte del tiempo debido a pura suerte.
Pero luego el aspecto del aprendizaje automático comenzaría a tomar el relevo. Comenzaría a asociar ciertas características con cierto resultado. Por ejemplo, es probable que las arañas peludas sean tarántulas, al igual que las arañas más grandes. Entonces, cada vez que aparezca una nueva araña que sea grande y peluda, se le asignará una mayor probabilidad de ser tarántula. Observe, todavía estamos trabajando con probabilidades, esto se debe a que inherentemente estamos trabajando con un algoritmo probabilístico.
La parte de aprendizaje funciona alterando las probabilidades. Inicialmente, el algoritmo comienza asignando aleatoriamente etiquetas de 'especie' a los individuos haciendo correlaciones aleatorias como, ser 'peludo' y ser 'papá piernas largas'. Cuando hace tal correlación y el conjunto de datos de entrenamiento no parece estar de acuerdo con él, esa suposición se descarta.
Del mismo modo, cuando una correlación funciona bien a través de varios ejemplos, se vuelve más fuerte cada vez. Este método de tropezar hacia la verdad es notablemente efectivo, gracias a muchas de las sutilezas matemáticas de las que, como principiante, no querrás preocuparte.
TensorFlow y entrenamiento de tu propio clasificador de flores
TensorFlow lleva la idea del aprendizaje automático aún más lejos. En el ejemplo anterior, usted estuvo a cargo de determinar las características que distinguen a una especie de araña de otra. Tuvimos que medir arañas individuales minuciosamente y crear cientos de registros de este tipo.
Pero podemos hacerlo mejor, al proporcionar solo datos de imagen sin procesar al algoritmo, podemos dejar que el algoritmo encuentre patrones y comprenda varias cosas sobre la imagen, como reconocer las formas en la imagen, luego comprender cuál es la textura de las diferentes superficies, el color , así sucesivamente. Esta es la noción inicial de la visión por computadora y también puede usarla para otro tipo de entradas, como señales de audio y entrenamiento de su algoritmo para el reconocimiento de voz. Todo esto viene bajo el término general de 'Deep Learning', donde el aprendizaje automático se lleva a su extremo lógico.
Este conjunto generalizado de nociones puede luego especializarse al tratar con muchas imágenes de flores y clasificarlas.
En el siguiente ejemplo usaremos un Python2.7 front-end para interactuar con TensorFlow y usaremos pip (no pip3) para instalar TensorFlow. El soporte de Python 3 todavía tiene algunos errores.
Para crear su propio clasificador de imágenes, use TensorFlow primero, instálelo usando pepita:
$ pip instalar tensorflowA continuación, necesitamos clonar el tensorflow-para-poetas-2 repositorio de git. Este es un buen lugar para comenzar por dos razones:
- Es simple y fácil de usar
- Viene pre-entrenado hasta cierto punto. Por ejemplo, el clasificador de flores ya está capacitado para comprender qué textura está mirando y qué formas está mirando, por lo que es computacionalmente menos intensivo.
Consigamos el repositorio:
$ git clon https: // github.com / googlecodelabs / tensorflow-for-poets-2$ cd tensorflow-para-poetas-2
Este va a ser nuestro directorio de trabajo, por lo que todos los comandos deben emitirse desde él, a partir de ahora.
Todavía necesitamos entrenar el algoritmo para el problema específico de reconocer flores, para eso necesitamos datos de entrenamiento, así que consigamos eso:
$ curl http: // descargar.tensorflow.org / example_images / flower_photos.tgz| tar xz -C archivos_tf
El directorio… ./tensorflow-para-poetas-2 / tf_files contiene una tonelada de estas imágenes debidamente etiquetadas y listas para ser utilizadas. Las imágenes tendrán dos finalidades distintas:
- Entrenamiento del programa ML
- Probando el programa ML
Puedes comprobar el contenido de la carpeta tf_files y aquí encontrará que nos estamos reduciendo a solo 5 categorías de flores, a saber, margaritas, tulipanes, girasoles, diente de león y rosas.
Entrenando el modelo
Puede iniciar el proceso de formación configurando primero las siguientes constantes para cambiar el tamaño de todas las imágenes de entrada a un tamaño estándar y utilizando una arquitectura de red móvil ligera:
$ IMAGE_SIZE = 224$ ARQUITECTURA = "mobilenet_0.50 _ $ IMAGE_SIZE "
Luego, invoque el script de Python ejecutando el comando:
$ python -m scripts.reentrenamiento \--bottleneck_dir = archivos_tf / cuellos de botella \
--how_many_training_steps = 500 \
--dir_modelo = archivos_tf / modelos / \
--resúmenes_dir = tf_files / training_summaries / "$ ARQUITECTURA" \
--output_graph = tf_files / retrained_graph.pb \
--output_labels = tf_files / retrained_labels.TXT \
--arquitectura = "$ ARQUITECTURA" \
--image_dir = tf_files / flower_photos
Si bien hay muchas opciones especificadas aquí, la mayoría de ellas especifican sus directorios de datos de entrada y el número de iteraciones, así como los archivos de salida donde se almacenaría la información sobre el nuevo modelo. Esto no debería tardar más de 20 minutos en ejecutarse en una computadora portátil mediocre.
Una vez que el script finalice tanto el entrenamiento como las pruebas, le dará una estimación de precisión del modelo entrenado, que en nuestro caso fue ligeramente superior al 90%.
Usando el modelo entrenado
Ahora está listo para utilizar este modelo para el reconocimiento de imágenes de cualquier imagen nueva de una flor. Usaremos esta imagen:

La cara del girasol es apenas visible y este es un gran desafío para nuestro modelo:
Para obtener esta imagen de Wikimedia commons use wget:
$ wget https: // cargar.wikimedia.org / wikipedia / commons / 2/28 / Sunflower_head_2011_G1.jpg$ mv Sunflower_head_2011_G1.jpg tf_files / desconocido.jpg
Se guarda como desconocido.jpg bajo la tf_files subdirectorio.
Ahora, por el momento de la verdad, veremos qué tiene que decir nuestro modelo sobre esta imagen.Para hacer eso, invocamos el label_image texto:
$ python -m scripts.label_image --graph = tf_files / retrained_graph.pb --imagen = tf_files / unknown.jpg
Obtendría una salida similar a esta:
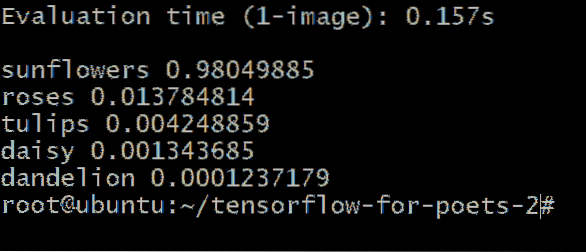
Los números junto al tipo de flor representan la probabilidad de que nuestra imagen desconocida pertenezca a esa categoría. Por ejemplo, es 98.04% seguro de que la imagen es de un girasol y es solo 1.37% de probabilidad de que sea una rosa.
Conclusión
Incluso con unos recursos computacionales muy mediocres, estamos viendo una precisión asombrosa en la identificación de imágenes. Esto demuestra claramente el poder y la flexibilidad de TensorFlow.
A partir de aquí, puede comenzar a experimentar con otros tipos de entradas o intentar comenzar a escribir su propia aplicación diferente usando Python y TensorFlow. Si quieres conocer un poco mejor el funcionamiento interno del aprendizaje automático, aquí tienes una forma interactiva de hacerlo.