En este artículo, analizaremos los usos básicos de un grupo por función en Python de panda. Todos los comandos se ejecutan en el editor de Pycharm.
Discutamos el concepto principal del grupo con la ayuda de los datos del empleado. Hemos creado un marco de datos con algunos detalles útiles de los empleados (Employee_Names, Designation, Employee_city, Age).
Concatenación de cadenas usando Agrupar por función
Usando la función groupby, puede concatenar cadenas. Los mismos registros se pueden unir con ',' en una sola celda.
Ejemplo
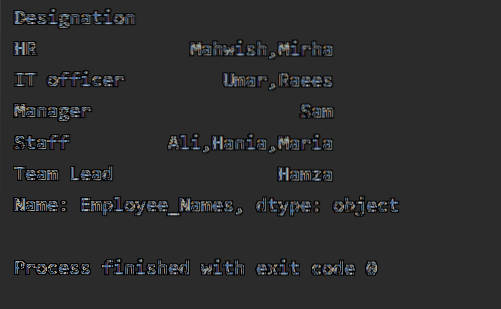
En el siguiente ejemplo, hemos ordenado los datos en función de la columna 'Designación' de los empleados y unimos los Empleados que tienen la misma designación. La función lambda se aplica en 'Employees_Name'.
importar pandas como pddf = pd.Marco de datos(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designación': ['Gerente', 'Personal', 'Oficial de TI', 'Oficial de TI', 'Recursos humanos', 'Personal', 'Recursos humanos', 'Personal', 'Líder de equipo'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ("Designación") ['Employee_Names'].aplicar (lambda Employee_Names: ','.unirse (Employee_Names))
imprimir (df1)
Cuando se ejecuta el código anterior, se muestra la siguiente salida:
Clasificación de valores en orden ascendente
Use el objeto groupby en un marco de datos regular llamando a '.to_frame () 'y luego use reset_index () para reindexar. Ordene los valores de columna llamando a sort_values ().
Ejemplo
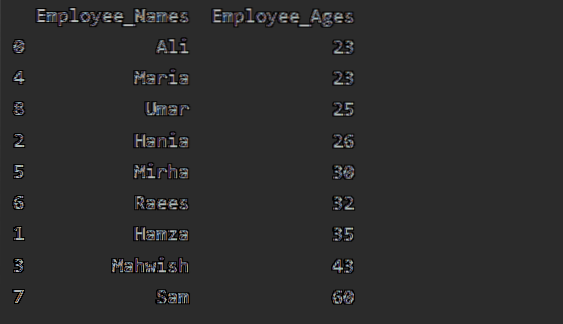
En este ejemplo, ordenaremos la edad del empleado en orden ascendente. Usando el siguiente fragmento de código, hemos recuperado 'Employee_Age' en orden ascendente con 'Employee_Names'.
importar pandas como pddf = pd.Marco de datos(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designación': ['Gerente', 'Personal', 'Oficial de TI', 'Oficial de TI', 'Recursos humanos', 'Personal', 'Recursos humanos', 'Personal', 'Líder de equipo'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Employee_Age'].suma().enmarcar().reset_index ().sort_values (por = 'Employee_Age')
imprimir (df1)
Uso de agregados con groupby
Hay una serie de funciones o agregaciones disponibles que puede aplicar en grupos de datos como count (), sum (), mean (), median (), mode (), std (), min (), max ().
Ejemplo
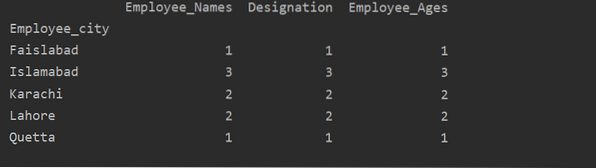
En este ejemplo, hemos utilizado una función 'count ()' con groupby para contar los Empleados que pertenecen a la misma 'Employee_city'.
importar pandas como pddf = pd.Marco de datos(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designación': ['Gerente', 'Personal', 'Oficial de TI', 'Oficial de TI', 'Recursos humanos', 'Personal', 'Recursos humanos', 'Personal', 'Líder de equipo'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Ciudad_empleado').contar()
imprimir (df1)
Como puede ver el siguiente resultado, en las columnas Designation, Employee_Names y Employee_Age, cuente los números que pertenecen a la misma ciudad:
Visualice datos usando groupby
Mediante el uso de 'import matplotlib.pyplot ', puede visualizar sus datos en gráficos.
Ejemplo
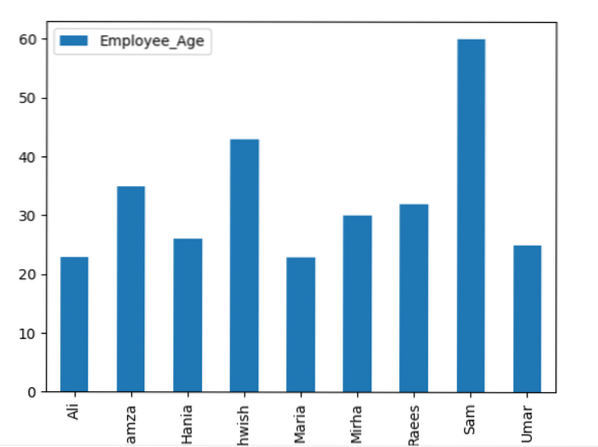
Aquí, el siguiente ejemplo visualiza el 'Employee_Age' con 'Employee_Nmaes' del DataFrame dado usando la declaración groupby.
importar pandas como pdimportar matplotlib.pyplot como plt
marco de datos = pd.Marco de datos(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designación': ['Gerente', 'Personal', 'Oficial de TI', 'Oficial de TI', 'Recursos humanos', 'Personal', 'Recursos humanos', 'Personal', 'Líder de equipo'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf ()
marco de datos.groupby ('Nombre_empleado').suma().trama (tipo = 'barra')
plt.show()
Ejemplo
Para trazar el gráfico apilado usando groupby, gire el 'apilado = verdadero' y use el siguiente código:
importar pandas como pdimportar matplotlib.pyplot como plt
df = pd.Marco de datos(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designación': ['Gerente', 'Personal', 'Oficial de TI', 'Oficial de TI', 'Recursos humanos', 'Personal', 'Recursos humanos', 'Personal', 'Líder de equipo'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
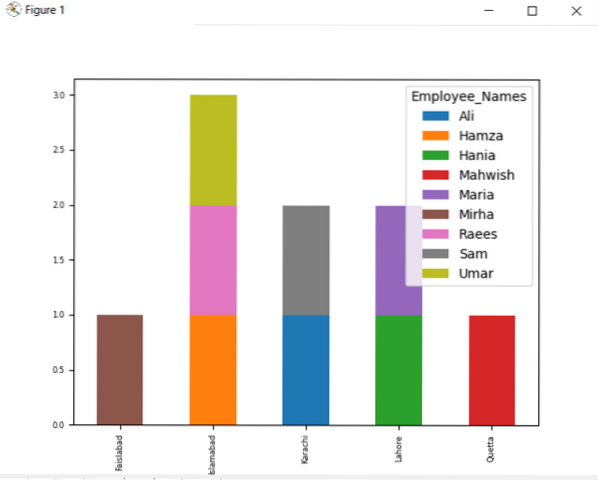
df.groupby (['Employee_city', 'Employee_Names']).Talla().desapilar ().trama (tipo = 'barra', apilado = verdadero, tamaño de fuente = '6')
plt.show()
En el gráfico que se muestra a continuación, el número de empleados apilados que pertenecen a la misma ciudad.
Cambiar el nombre de la columna con el grupo por
También puede cambiar el nombre de la columna agregada con un nuevo nombre modificado de la siguiente manera:
importar pandas como pdimportar matplotlib.pyplot como plt
df = pd.Marco de datos(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designación': ['Gerente', 'Personal', 'Oficial de TI', 'Oficial de TI', 'Recursos humanos', 'Personal', 'Recursos humanos', 'Personal', 'Líder de equipo'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
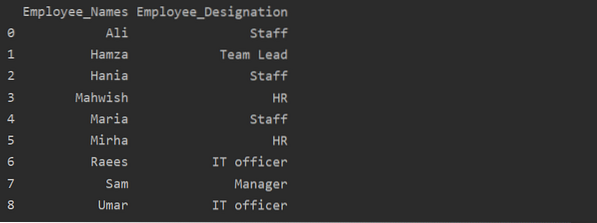
df1 = df.groupby ('Employee_Names') ['Designación'].suma().reset_index (nombre = 'Employee_Designation')
imprimir (df1)
En el ejemplo anterior, el nombre de 'Designación' se cambia a 'Employee_Designation'.
Recuperar grupo por clave o valor
Usando la declaración groupby, puede recuperar registros o valores similares del marco de datos.
Ejemplo
En el ejemplo que se muestra a continuación, tenemos datos de grupo basados en 'Designación'. Luego, el grupo 'Personal' se recupera usando el .getgroup ('Personal').
importar pandas como pdimportar matplotlib.pyplot como plt
df = pd.Marco de datos(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designación': ['Gerente', 'Personal', 'Oficial de TI', 'Oficial de TI', 'Recursos humanos', 'Personal', 'Recursos humanos', 'Personal', 'Líder de equipo'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
extract_value = df.groupby ('Designación')
imprimir (extraer_valor.get_group ('Personal'))
El siguiente resultado se muestra en la ventana de salida:

Agregar valor a la lista del grupo
Se pueden mostrar datos similares en forma de lista utilizando la instrucción groupby. Primero, agrupe los datos según una condición. Luego, aplicando la función, puede colocar fácilmente este grupo en las listas.
Ejemplo
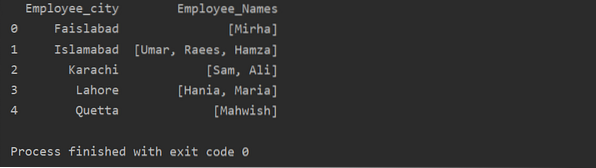
En este ejemplo, hemos insertado registros similares en la lista de grupos. Todos los empleados se dividen en el grupo según 'Employee_city', y luego, al aplicar la función 'Lambda', este grupo se recupera en forma de lista.
importar pandas como pddf = pd.Marco de datos(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designación': ['Gerente', 'Personal', 'Oficial de TI', 'Oficial de TI', 'Recursos humanos', 'Personal', 'Recursos humanos', 'Personal', 'Líder de equipo'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city') ['Employee_Names'].aplicar (lambda group_series: group_series.Listar()).reset_index ()
imprimir (df1)
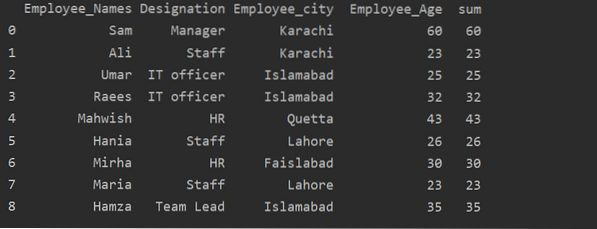
Uso de la función de transformación con groupby
Los empleados se agrupan según su edad, estos valores se suman y, al usar la función 'transformar', se agrega una nueva columna en la tabla:
importar pandas como pddf = pd.Marco de datos(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designación': ['Gerente', 'Personal', 'Oficial de TI', 'Oficial de TI', 'Recursos humanos', 'Personal', 'Recursos humanos', 'Personal', 'Líder de equipo'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df ['suma'] = df.groupby (['Employee_Names']) ['Employee_Age'].transformar ('suma')
imprimir (df)
Conclusión
Hemos explorado los diferentes usos de la declaración groupby en este artículo. Hemos mostrado cómo puede dividir los datos en grupos y, al aplicar diferentes agregaciones o funciones, puede recuperar fácilmente estos grupos.


