Una tubería es un medio de comunicación entre procesos. Un proceso escribe datos en la tubería y otro proceso lee los datos de la tubería. En este artículo, veremos cómo se usa la función pipe () para implementar el concepto usando lenguaje C.
Acerca de Pipe
En la tubería, los datos se mantienen en un orden FIFO, lo que significa escribir datos en un extremo de la tubería de forma secuencial y leer datos de otro extremo de la tubería en el mismo orden secuencial.
Si algún proceso lee desde la tubería, pero ningún otro proceso aún no ha escrito en la tubería, entonces read devuelve el final del archivo. Si un proceso quiere escribir en una tubería, pero no hay otro proceso adjunto a la tubería para lectura, entonces esta es una condición de error y la tubería genera una señal SIGPIPE.
Archivo de cabecera
#incluirSintaxis
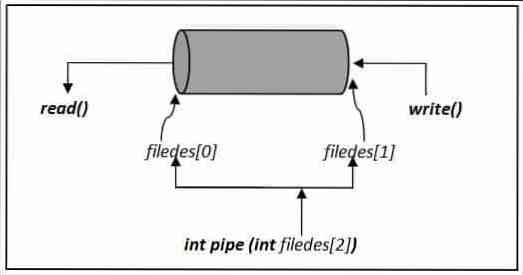
int pipe (int filedes [2])Argumentos
Esta función toma un solo argumento, una matriz de dos enteros (filedes). filedes [0] se utiliza para leer desde la tubería, y filedes [1] se usa para escribir en la tubería. El proceso que quiere leer desde la tubería debe cerrarse filedes [1], y el proceso que quiere escribir en la tubería debería cerrarse filedes [0]. Si los extremos innecesarios de la tubería no se cierran explícitamente, nunca se devolverá el final del archivo (EOF).
Valores devueltos
En el éxito, el tubo() devuelve 0, en caso de error, la función devuelve -1.
Pictóricamente, podemos representar el tubo() funcionan de la siguiente manera:
A continuación se muestran algunos ejemplos que muestran cómo usar la función de tubería en lenguaje C.
Ejemplo 1
En este ejemplo, veremos cómo funciona la función de tubería. Aunque usar una tubería en un solo proceso no es muy útil, nos daremos una idea.
// Ejemplo 1.C#incluir
#incluir
#incluir
#incluir
int main ()
int n;
int filedes [2];
tampón char [1025];
char * message = "Hola, mundo!";
tubería (filedes);
escribir (filedes [1], mensaje, strlen (mensaje));
if ((n = read (filedes [0], buffer, 1024))> = 0)
tampón [n] = 0; // termina la cadena
printf ("leer% d bytes de la tubería:"% s "\ n", n, búfer);
demás
perror ("leer");
salir (0);
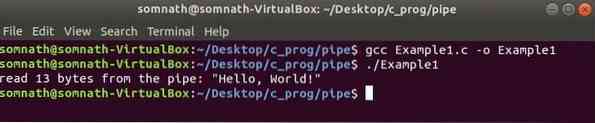
Aquí primero hemos creado una tubería usando tubo() función luego se escribe en la tubería usando fildes [1] final. Luego, los datos se han leído usando el otro extremo de la tubería, que es filedes [0]. Para leer y escribir en el archivo, solíamos leer() y escribir() funciones.
Ejemplo 2
En este ejemplo, veremos cómo los procesos padre e hijo se comunican usando la tubería.
// Ejemplo2.C#incluir
#incluir
#incluir
#incluir
#incluir
int main ()
int filedes [2], nbytes;
pid_t childpid;
char string [] = "Hola, mundo!\norte";
búfer de lectura de caracteres [80];
tubería (filedes);
si ((childpid = fork ()) == -1)
perror ("tenedor");
salida (1);
si (childpid == 0)
close (filedes [0]); // El proceso hijo no necesita este extremo de la tubería
/ * Enviar "cadena" a través del lado de salida de la tubería * /
escribir (filedes [1], cadena, (strlen (cadena) +1));
salir (0);
demás
/ * El proceso padre cierra el lado de salida de la tubería * /
close (filedes [1]); // El proceso principal no necesita este extremo de la tubería
/ * Leer en una cadena de la tubería * /
nbytes = read (filedes [0], readbuffer, sizeof (readbuffer));
printf ("Leer cadena:% s", readbuffer);
return (0);

Primero, se ha creado una tubería usando la función de tubería y luego se ha bifurcado un proceso hijo. Luego, el proceso hijo cierra el extremo de lectura y escribe en la tubería. El proceso padre cierra el extremo de escritura y lee de la tubería y lo muestra. Aquí el flujo de datos es solo una forma que es de un niño a un padre.
Conclusión:
tubo() es una poderosa llamada al sistema en Linux. En este artículo, hemos visto solo un flujo de datos unidireccional, un proceso escribe y otro proceso lee, creando dos conductos que también podemos lograr un flujo de datos bidireccional.


