En este artículo, le mostraré cómo instalar y usar CURL en Ubuntu 18.04 Castor biónico. Empecemos.
Instalación de CURL
Primero actualice la caché del repositorio de paquetes de su máquina Ubuntu con el siguiente comando:
$ sudo apt-get update
La caché del repositorio de paquetes debe actualizarse.
CURL está disponible en el repositorio oficial de paquetes de Ubuntu 18.04 Castor biónico.
Puede ejecutar el siguiente comando para instalar CURL en Ubuntu 18.04:
$ sudo apt-get install curl
CURL debe estar instalado.
Usando CURL
En esta sección del artículo, le mostraré cómo usar CURL para diferentes tareas relacionadas con HTTP.
Comprobando una URL con CURL
Puede verificar si una URL es válida o no con CURL.
Puede ejecutar el siguiente comando para verificar si una URL, por ejemplo, https: // www.Google.com es válido o no.
$ curl https: // www.Google.com
Como puede ver en la captura de pantalla a continuación, se muestran muchos textos en el terminal. Significa la URL https: // www.Google.com es válido.
Ejecuté el siguiente comando solo para mostrarte cómo se ve una URL incorrecta.
$ curl http: // notfound.extraviado
Como puede ver en la captura de pantalla a continuación, dice No se pudo resolver el host. Significa que la URL no es válida.
Descarga de una página web con CURL
Puede descargar una página web desde una URL usando CURL.
El formato del comando es:
$ curl -o ARCHIVO URLAquí, FILENAME es el nombre o la ruta del archivo donde desea guardar la página web descargada. URL es la ubicación o dirección de la página web.
Digamos que desea descargar la página web oficial de CURL y guardarla como curl-official.archivo html. Ejecute el siguiente comando para hacer eso:
$ curl -o curl-oficial.html https: // curl.haxx.se / docs / httpscripting.html
La página web está descargada.

Como puede ver en la salida del comando ls, la página web se guarda en curl-official.archivo html.

También puede abrir el archivo con un navegador web como puede ver en la captura de pantalla a continuación.
Descarga de un archivo con CURL
También puede descargar un archivo de Internet usando CURL. CURL es uno de los mejores descargadores de archivos de línea de comandos. CURL también admite descargas reanudadas.
El formato del comando CURL para descargar un archivo de Internet es:
$ curl -O FILE_URLAquí FILE_URL es el enlace al archivo que desea descargar. La opción -O guarda el archivo con el mismo nombre que está en el servidor web remoto.
Por ejemplo, digamos que desea descargar el código fuente del servidor HTTP Apache de Internet con CURL. Ejecutaría el siguiente comando:
$ curl -O http: // www-eu.apache.org / dist // httpd / httpd-2.4.29.alquitrán.gz
El archivo se está descargando.

El archivo se descarga al directorio de trabajo actual.

Puede ver en la sección marcada de la salida del comando ls a continuación, el http-2.4.29.alquitrán.gz que acabo de descargar.

Si desea guardar el archivo con un nombre diferente al del servidor web remoto, simplemente ejecute el comando de la siguiente manera.
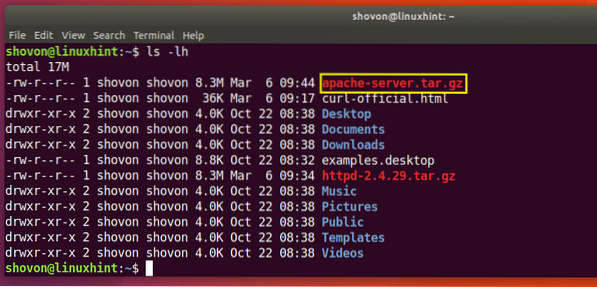
$ curl -o apache-servidor.alquitrán.gz http: // www-eu.apache.org / dist // httpd / httpd-2.4.29.alquitrán.gz
La descarga esta completa.

Como puede ver en la sección marcada de la salida del comando ls a continuación, el archivo se guarda con un nombre diferente.
Reanudación de descargas con CURL
También puede reanudar las descargas fallidas con CURL. Esto es lo que hace que CURL sea uno de los mejores descargadores de línea de comandos.
Si usó la opción -O para descargar un archivo con CURL y falló, ejecute el siguiente comando para reanudarlo nuevamente.
$ curl -C - -O YOUR_DOWNLOAD_LINKAquí YOUR_DOWNLOAD_LINK es la URL del archivo que intentó descargar con CURL pero falló.
Supongamos que estaba intentando descargar el archivo fuente del servidor HTTP Apache y su red se desconectó a la mitad y desea reanudar la descarga nuevamente.
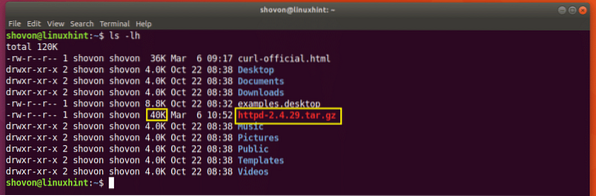
Ejecute el siguiente comando para reanudar la descarga con CURL:
$ curl -C - -O http: // www-eu.apache.org / dist // httpd / httpd-2.4.29.alquitrán.gz
Se reanuda la descarga.

Si ha guardado el archivo con un nombre diferente al que está en el servidor web remoto, entonces debe ejecutar el comando de la siguiente manera:
$ curl -C - -o NOMBRE DE ARCHIVO DOWNLOAD_LINKAquí FILENAME es el nombre del archivo que definió para la descarga. Recuerde que el NOMBRE DE ARCHIVO debe coincidir con el nombre de archivo que intentó guardar la descarga cuando falló la descarga.
Limite la velocidad de descarga con CURL
Puede tener una sola conexión a Internet conectada al enrutador Wi-Fi que todos los miembros de su familia u oficina están usando. Si descarga un archivo grande con CURL, otros miembros de la misma red pueden tener problemas cuando intenten usar Internet.
Puede limitar la velocidad de descarga con CURL si lo desea.
El formato del comando es:
$ curl - tasa límite DOWNLOAD_SPEED -O DOWNLOAD_LINKAquí DOWNLOAD_SPEED es la velocidad a la que desea descargar el archivo.
Digamos que desea que la velocidad de descarga sea de 10 KB, ejecute el siguiente comando para hacerlo:
$ curl - tasa límite 10K -O http: // www-eu.apache.org / dist // httpd / httpd-2.4.29.alquitrán.gz
Como puede ver, la velocidad se limita a 10 Kilo Bytes (KB), lo que equivale a casi 10000 bytes (B).

Obtener información de encabezado HTTP mediante CURL
Cuando trabaje con API REST o desarrolle sitios web, es posible que deba verificar los encabezados HTTP de una determinada URL para asegurarse de que su API o sitio web envíe los encabezados HTTP que desea. Puedes hacer eso con CURL.
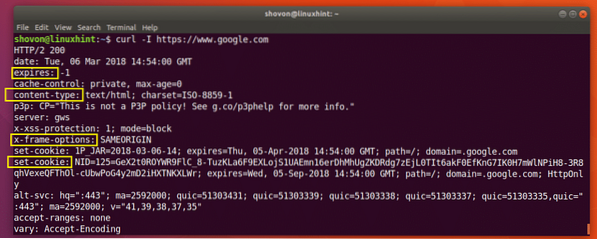
Puede ejecutar el siguiente comando para obtener la información del encabezado de https: // www.Google.com:
$ curl -I https: // www.Google.com
Como puede ver en la captura de pantalla siguiente, todos los encabezados de respuesta HTTP de https: // www.Google.com está en la lista.
Así es como instalas y usas CURL en Ubuntu 18.04 Castor biónico. Gracias por leer este artículo.


