Este es un artículo de seguimiento al anterior. Cubriremos cómo refinar la consulta, formular criterios de búsqueda más complejos con diferentes parámetros y comprender los diferentes formularios web de la página de consulta de Apache Solr. Además, discutiremos cómo posprocesar el resultado de la búsqueda utilizando diferentes formatos de salida como XML, CSV y JSON.
Consultando Apache Solr
Apache Solr está diseñado como una aplicación web y un servicio que se ejecuta en segundo plano. El resultado es que cualquier aplicación cliente puede comunicarse con Solr enviándole consultas (el tema central de este artículo), manipulando el núcleo del documento agregando, actualizando y eliminando datos indexados, y optimizando los datos centrales. Hay dos opciones: a través del panel / interfaz web o usando una API enviando la solicitud correspondiente.
Es común utilizar el primera opción con fines de prueba y no para acceso regular. La siguiente figura muestra el panel de la interfaz de usuario de administración de Apache Solr con los diferentes formularios de consulta en el navegador web Firefox.
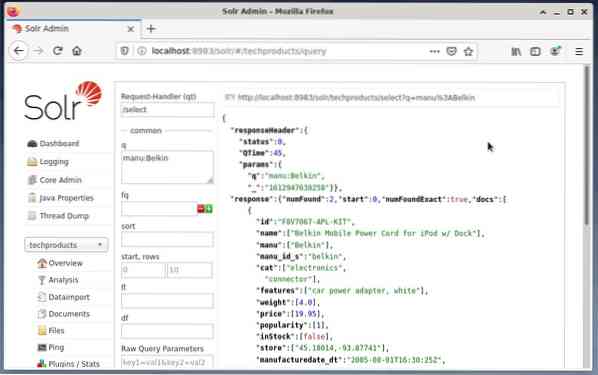
Primero, en el menú debajo del campo de selección principal, elija la entrada de menú "Consulta". A continuación, el tablero mostrará varios campos de entrada de la siguiente manera:
- Manejador de solicitudes (qt):
Defina qué tipo de solicitud le gustaría enviar a Solr. Puede elegir entre los controladores de solicitud predeterminados "/ select" (consultar datos indexados), "/ actualizar" (actualizar datos indexados) y "/ eliminar" (eliminar los datos indexados especificados), o uno autodefinido. - Evento de consulta (q):
Definir qué nombres de campo y valores se seleccionarán. - Filtrar consultas (fq):
Restrinja el superconjunto de documentos que se pueden devolver sin afectar la puntuación del documento. - Orden de clasificación (clasificación):
Defina el orden de clasificación de los resultados de la consulta en ascendente o descendente - Ventana de salida (inicio y filas):
Limita la salida a los elementos especificados - Lista de campos (fl):
Limita la información incluida en la respuesta de una consulta a una lista de campos especificada. - Formato de salida (peso):
Defina el formato de salida deseado. El valor predeterminado es JSON.
Al hacer clic en el botón Ejecutar consulta se ejecuta la solicitud deseada. Para ver ejemplos prácticos, eche un vistazo a continuación.
Como el segunda opción, puedes enviar una solicitud usando una API. Esta es una solicitud HTTP que cualquier aplicación puede enviar a Apache Solr. Solr procesa la solicitud y devuelve una respuesta. Un caso especial de esto es la conexión a Apache Solr a través de la API de Java. Esto se ha subcontratado a un proyecto independiente llamado SolrJ [7]: una API de Java sin necesidad de una conexión HTTP.
Sintaxis de la consulta
La sintaxis de la consulta se describe mejor en [3] y [5]. Los diferentes nombres de los parámetros se corresponden directamente con los nombres de los campos de entrada en los formularios explicados anteriormente. La siguiente tabla los enumera, además de ejemplos prácticos.
Índice de parámetros de consulta
| Parámetro | Descripción | Ejemplo |
|---|---|---|
| q | El parámetro de consulta principal de Apache Solr: los nombres y valores de los campos. Sus puntuaciones de similitud se documentan con los términos de este parámetro. | Id: 5 coches: * adilla * *: X5 |
| fq | Restringir el conjunto de resultados a los documentos de superconjunto que coinciden con el filtro, por ejemplo, definido mediante el analizador de consultas de rango de funciones | modelo id, modelo |
| comienzo | Compensaciones para los resultados de la página (comenzar). El valor predeterminado de este parámetro es 0. | 5 |
| filas | Compensaciones para los resultados de la página (fin). El valor de este parámetro es 10 por defecto | 15 |
| clasificar | Especifica la lista de campos separados por comas, según la cual se ordenarán los resultados de la consulta | modelo asc |
| Florida | Especifica la lista de campos que se devolverán para todos los documentos del conjunto de resultados | modelo id, modelo |
| peso | Este parámetro representa el tipo de escritor de respuesta que queríamos ver el resultado. El valor de esto es JSON por defecto. | json xml |
Las búsquedas se realizan a través de una solicitud HTTP GET con la cadena de consulta en el parámetro q. Los ejemplos a continuación aclararán cómo funciona esto. En uso está curl para enviar la consulta a Solr que está instalado localmente.
- Recupere todos los conjuntos de datos del curl de autos principal http: // localhost: 8983 / solr / cars / query?q = *: *
- Recupere todos los conjuntos de datos de los autos principales que tienen una identificación de 5 curl http: // localhost: 8983 / solr / cars / query?q = id: 5
- Recuperar el modelo de campo de todos los conjuntos de datos de los coches principales
Opción 1 (con escapado &): curl http: // localhost: 8983 / solr / cars / query?q = id: * \ & fl = modeloOpción 2 (consulta en ticks individuales):
curl 'http: // localhost: 8983 / solr / cars / query?q = id: * & fl = modelo ' - Recupere todos los conjuntos de datos de los automóviles principales ordenados por precio en orden descendente y genere los campos marca, modelo y precio, solo (versión en ticks individuales): curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * y
sort = precio desc &
fl = marca, modelo, precio ' - Recupere los primeros cinco conjuntos de datos de los automóviles principales ordenados por precio en orden descendente y genere los campos marca, modelo y precio, solo (versión en tics individuales): curl http: // localhost: 8983 / solr / cars / query - D '
q = *: * y
filas = 5 y
sort = precio desc &
fl = marca, modelo, precio ' - Recupere los primeros cinco conjuntos de datos de los automóviles principales ordenados por precio en orden descendente y genere los campos marca, modelo y precio más su puntaje de relevancia, solo (versión en ticks individuales): curl http: // localhost: 8983 / solr / coches / consulta -d '
q = *: * y
filas = 5 y
sort = precio desc &
fl = marca, modelo, precio, puntuación ' - Devuelve todos los campos almacenados, así como la puntuación de relevancia: curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * y
fl = *, puntuación '
Además, puede definir su propio controlador de solicitudes para enviar los parámetros de solicitud opcionales al analizador de consultas para controlar qué información se devuelve.
Analizadores de consultas
Apache Solr utiliza un analizador de consultas, un componente que traduce su cadena de búsqueda en instrucciones específicas para el motor de búsqueda. Un analizador de consultas se interpone entre usted y el documento que está buscando.
Solr viene con una variedad de tipos de analizadores que difieren en la forma en que se maneja una consulta enviada. El analizador de consultas estándar funciona bien para consultas estructuradas, pero es menos tolerante con los errores de sintaxis. Al mismo tiempo, tanto el analizador de consultas DisMax como el DisMax extendido están optimizados para consultas similares al lenguaje natural. Están diseñados para procesar frases simples ingresadas por los usuarios y para buscar términos individuales en varios campos usando diferentes ponderaciones.
Además, Solr también ofrece las llamadas consultas de función que permiten combinar una función con una consulta para generar una puntuación de relevancia específica. Estos analizadores se denominan Analizador de consultas de funciones y Analizador de consultas de rango de funciones. El siguiente ejemplo muestra el último para seleccionar todos los conjuntos de datos para "bmw" (almacenados en el campo de datos make) con los modelos del 318 al 323:
curl http: // localhost: 8983 / solr / cars / query -d 'q = hacer: bmw y
fq = modelo: [318 TO 323] '
Post-procesamiento de resultados
El envío de consultas a Apache Solr es una parte, pero el posprocesamiento del resultado de la búsqueda de la otra. Primero, puede elegir entre diferentes formatos de respuesta, desde JSON a XML, CSV y un formato Ruby simplificado. Simplemente especifique el parámetro wt correspondiente en una consulta. El siguiente ejemplo de código demuestra esto para recuperar el conjunto de datos en formato CSV para todos los elementos que usan curl con & escapado:
curl http: // localhost: 8983 / solr / cars / query?q = identificación: 5 \ & wt = csvLa salida es una lista separada por comas de la siguiente manera:

Para recibir el resultado como datos XML, pero los dos campos de salida hacen y modelan, ejecute la siguiente consulta:
curl http: // localhost: 8983 / solr / cars / query?q = *: * \ & fl = marca, modelo \ & wt = xmlLa salida es diferente y contiene tanto el encabezado de respuesta como la respuesta real:
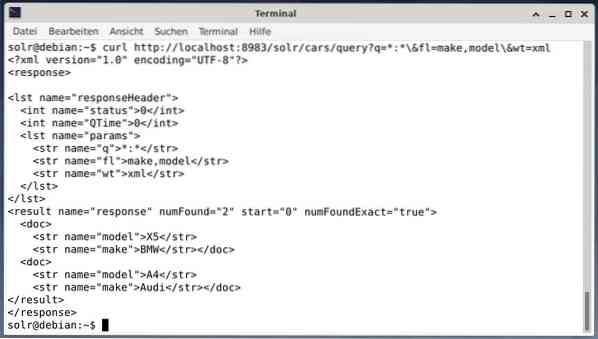
Wget simplemente imprime los datos recibidos en stdout. Esto le permite posprocesar la respuesta utilizando herramientas de línea de comandos estándar. Para enumerar algunos, contiene jq [9] para JSON, xsltproc, xidel, xmlstarlet [10] para XML y csvkit [11] para formato CSV.
Conclusión
Este artículo muestra diferentes formas de enviar consultas a Apache Solr y explica cómo procesar el resultado de la búsqueda. En la siguiente parte, aprenderá a usar Apache Solr para buscar en PostgreSQL, un sistema de administración de bases de datos relacionales.
Sobre los autores
Jacqui Kabeta es ambientalista, ávida investigadora, capacitadora y mentora. En varios países africanos, ha trabajado en la industria de la tecnología de la información y entornos de ONG.
Frank Hofmann es desarrollador de TI, formador y autor y prefiere trabajar desde Berlín, Ginebra y Ciudad del Cabo. Coautor del Libro de administración de paquetes de Debian disponible en dpmb.org
Enlaces y referencias
- [1] Apache Solr, https: // lucene.apache.org / solr /
- [2] Frank Hofmann y Jacqui Kabeta: Introducción a Apache Solr. Parte 1, http: // linuxhint.com
- [3] Yonik Seelay: Sintaxis de consulta Solr, http: // yonik.com / solr / query-syntax /
- [4] Yonik Seelay: Tutorial de Solr, http: // yonik.com / solr-tutorial /
- [5] Apache Solr: Consulta de datos, Tutorialspoint, https: // www.tutorialspoint.com / apache_solr / apache_solr_querying_data.htm
- [6] Lucene, https: // lucene.apache.org /
- [7] SolrJ, https: // lucene.apache.org / solr / guide / 8_8 / using-solrj.html
- [8] rizo, https: // rizo.se /
- [9] jq, https: // github.com / stedolan / jq
- [10] xmlstarlet, http: // xmlstar.fuenteforja.neto/
- [11] csvkit, https: // csvkit.readthedocs.io / en / ultimo /


