Los tutoriales de web scraping se han cubierto en el pasado, por lo tanto, este tutorial solo cubre el aspecto de obtener acceso a sitios web iniciando sesión con código en lugar de hacerlo manualmente usando el navegador.
Para comprender este tutorial y poder escribir scripts para iniciar sesión en sitios web, necesitará algunos conocimientos de HTML. Tal vez no lo suficiente para crear sitios web increíbles, pero lo suficiente para comprender la estructura de una página web básica.
Instalación
Esto se haría con las bibliotecas Requests y BeautifulSoup Python. Aparte de esas bibliotecas de Python, necesitaría un buen navegador como Google Chrome o Mozilla Firefox, ya que serían importantes para el análisis inicial antes de escribir el código.
Las bibliotecas Requests y BeautifulSoup se pueden instalar con el comando pip desde la terminal como se ve a continuación:
solicitudes de instalación de pippip instalar BeautifulSoup4
Para confirmar el éxito de la instalación, active el shell interactivo de Python que se hace escribiendo pitón en la terminal.
Luego importe ambas bibliotecas:
solicitudes de importacióndesde bs4 importar BeautifulSoup
La importación se realiza correctamente si no hay errores.
El proceso
Iniciar sesión en un sitio web con scripts requiere conocimientos de HTML y una idea de cómo funciona la web. Veamos brevemente cómo funciona la web.
Los sitios web se componen de dos partes principales, el lado del cliente y el lado del servidor. El lado del cliente es la parte de un sitio web con el que interactúa el usuario, mientras que el lado del servidor es la parte del sitio web donde se ejecutan la lógica empresarial y otras operaciones del servidor, como el acceso a la base de datos.
Cuando intenta abrir un sitio web a través de su enlace, está haciendo una solicitud al lado del servidor para buscar los archivos HTML y otros archivos estáticos como CSS y JavaScript. Esta solicitud se conoce como solicitud GET. Sin embargo, cuando está completando un formulario, cargando un archivo multimedia o un documento, creando una publicación y haciendo clic, digamos, en un botón de envío, está enviando información al lado del servidor. Esta solicitud se conoce como solicitud POST.
Comprender esos dos conceptos sería importante al escribir nuestro guión.
Inspeccionando el sitio web
Para practicar los conceptos de este artículo, estaríamos usando el sitio web Quotes To Scrape.
Iniciar sesión en sitios web requiere información como el nombre de usuario y una contraseña.
Sin embargo, dado que este sitio web solo se utiliza como prueba de concepto, todo vale. Por lo tanto estaríamos usando administración como nombre de usuario y 12345 como la contraseña.
En primer lugar, es importante ver la fuente de la página, ya que esto daría una descripción general de la estructura de la página web. Esto se puede hacer haciendo clic derecho en la página web y haciendo clic en "Ver fuente de la página". A continuación, inspecciona el formulario de inicio de sesión. Para ello, haga clic con el botón derecho en uno de los cuadros de inicio de sesión y haga clic en inspeccionar elemento. Al inspeccionar el elemento, debería ver aporte etiquetas y luego un padre formulario etiqueta en algún lugar por encima de ella. Esto muestra que los inicios de sesión son básicamente formas CORREOed al lado del servidor del sitio web.
Ahora, observe el nombre atributo de las etiquetas de entrada para los cuadros de nombre de usuario y contraseña, serían necesarios al escribir el código. Para este sitio web, el nombre atributo para el nombre de usuario y la contraseña son nombre de usuario y contraseña respectivamente.
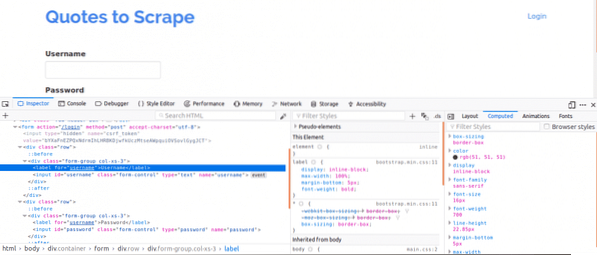
A continuación, tenemos que saber si hay otros parámetros que serían importantes para iniciar sesión. Expliquemos esto rápidamente. Para aumentar la seguridad de los sitios web, los tokens generalmente se generan para evitar ataques de falsificación entre sitios.
Por lo tanto, si esos tokens no se agregan a la solicitud POST, el inicio de sesión fallará. Entonces, ¿cómo sabemos acerca de tales parámetros??
Necesitaríamos usar la pestaña Red. Para obtener esta pestaña en Google Chrome o Mozilla Firefox, abra las Herramientas para desarrolladores y haga clic en la pestaña Red.
Una vez que esté en la pestaña de red, intente actualizar la página actual y notará que llegan solicitudes. Debe intentar tener cuidado con las solicitudes POST que se envían cuando intentamos iniciar sesión.
Esto es lo que haríamos a continuación, mientras tenemos la pestaña Red abierta. Ingrese los detalles de inicio de sesión e intente iniciar sesión, la primera solicitud que verá debería ser la solicitud POST.
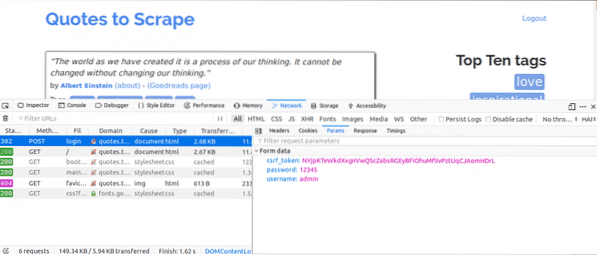
Haga clic en la solicitud POST y vea los parámetros del formulario. Notaría que el sitio web tiene una csrf_token parámetro con un valor. Ese valor es un valor dinámico, por lo tanto, necesitaríamos capturar dichos valores usando el OBTENER solicitar primero antes de usar el CORREO pedido.
Para otros sitios web en los que estaría trabajando, probablemente no vea el csrf_token pero puede haber otros tokens que se generen dinámicamente. Con el tiempo, mejorará su conocimiento de los parámetros que realmente importan al intentar iniciar sesión.
El código
En primer lugar, necesitamos usar Requests y BeautifulSoup para obtener acceso al contenido de la página de inicio de sesión.
desde la sesión de importación de solicitudesdesde bs4 importar BeautifulSoup como bs
con Session () como s:
sitio = s.get ("http: // comillas.raspar.com / login ")
imprimir (sitio.contenido)
Esto imprimiría el contenido de la página de inicio de sesión antes de iniciar sesión y si busca la palabra clave "Iniciar sesión". La palabra clave se encontraría en el contenido de la página, lo que indica que aún no hemos iniciado sesión.
A continuación, buscaríamos el csrf_token palabra clave que se encontró como uno de los parámetros al usar la pestaña de red anteriormente. Si la palabra clave muestra una coincidencia con un aporte , el valor se puede extraer cada vez que ejecute el script usando BeautifulSoup.
desde la sesión de importación de solicitudesdesde bs4 importar BeautifulSoup como bs
con Session () como s:
sitio = s.get ("http: // comillas.raspar.com / login ")
bs_content = bs (sitio.contenido, "html.analizador ")
token = bs_content.buscar ("entrada", "nombre": "csrf_token") ["valor"]
login_data = "nombre de usuario": "admin", "contraseña": "12345", "csrf_token": token
s.post ("http: // comillas.raspar.com / login ", login_data)
home_page = s.get ("http: // comillas.raspar.com ")
imprimir (home_page.contenido)
Esto imprimiría el contenido de la página después de iniciar sesión y si busca la palabra clave "Cerrar sesión". La palabra clave se encontraría en el contenido de la página, lo que muestra que pudimos iniciar sesión correctamente.
Echemos un vistazo a cada línea de código.
desde la sesión de importación de solicitudesdesde bs4 importar BeautifulSoup como bs
Las líneas de código anteriores se usan para importar el objeto Session de la biblioteca de solicitudes y el objeto BeautifulSoup de la biblioteca bs4 usando un alias de bs.
con Session () como s:La sesión de solicitudes se utiliza cuando tiene la intención de mantener el contexto de una solicitud, por lo que se pueden almacenar las cookies y toda la información de esa sesión de solicitud.
bs_content = bs (sitio.contenido, "html.analizador ")token = bs_content.buscar ("entrada", "nombre": "csrf_token") ["valor"]
Este código aquí utiliza la biblioteca BeautifulSoup para que el csrf_token se puede extraer de la página web y luego asignar a la variable token. Puede aprender a extraer datos de los nodos usando BeautifulSoup.
login_data = "nombre de usuario": "admin", "contraseña": "12345", "csrf_token": tokens.post ("http: // comillas.raspar.com / login ", login_data)
El código aquí crea un diccionario de los parámetros que se utilizarán para iniciar sesión. Las claves de los diccionarios son las nombre atributos de las etiquetas de entrada y los valores son los valor atributos de las etiquetas de entrada.
La correo El método se utiliza para enviar una solicitud de publicación con los parámetros e iniciar sesión.
home_page = s.get ("http: // comillas.raspar.com ")imprimir (página_inicial.contenido)
Después de iniciar sesión, estas líneas de código anteriores simplemente extraen la información de la página para mostrar que el inicio de sesión fue exitoso.
Conclusión
El proceso de iniciar sesión en sitios web usando Python es bastante fácil, sin embargo, la configuración de los sitios web no es la misma, por lo que algunos sitios resultarían más difíciles de iniciar sesión que otros. Se puede hacer más para superar cualquier desafío de inicio de sesión que tenga.
Lo más importante de todo esto es el conocimiento de HTML, Solicitudes, BeautifulSoup y la capacidad de comprender la información obtenida de la pestaña Red de las herramientas de desarrollador de su navegador web.


