En esta lección de Machine Learning con scikit-learn, aprenderemos varios aspectos de este excelente paquete de Python que nos permite aplicar capacidades simples y complejas de Machine Learning en un conjunto diverso de datos junto con funcionalidades para probar la hipótesis que establecemos.
El paquete scikit-learn contiene herramientas simples y eficientes para aplicar la minería de datos y el análisis de datos en conjuntos de datos y estos algoritmos están disponibles para ser aplicados en diferentes contextos. Es un paquete de código abierto disponible bajo una licencia BSD, lo que significa que podemos usar esta biblioteca incluso comercialmente. Está construido sobre matplotlib, NumPy y SciPy, por lo que es de naturaleza versátil. Usaremos Anaconda con el cuaderno Jupyter para presentar ejemplos en esta lección.
Que proporciona scikit-learn?
La biblioteca scikit-learn se centra completamente en el modelado de datos. Tenga en cuenta que no hay funcionalidades importantes presentes en scikit-learn cuando se trata de cargar, manipular y resumir datos. Estos son algunos de los modelos populares que nos proporciona scikit-learn:
- Agrupación para agrupar datos etiquetados
- Conjuntos de datos para proporcionar conjuntos de datos de prueba e investigar los comportamientos del modelo
- Validación cruzada para estimar el rendimiento de modelos supervisados sobre datos no vistos
- Métodos de conjunto a combinar las predicciones de múltiples modelos supervisados
- Extracción de características para definir atributos en datos de imagen y texto
Instalar Python scikit-learn
Solo una nota antes de comenzar el proceso de instalación, usamos un entorno virtual para esta lección que hicimos con el siguiente comando:
pitón -m virtualenv scikitfuente scikit / bin / enable
Una vez que el entorno virtual está activo, podemos instalar la biblioteca pandas dentro del entorno virtual para que se puedan ejecutar los ejemplos que creamos a continuación:
pip instalar scikit-learnO podemos usar Conda para instalar este paquete con el siguiente comando:
conda instalar scikit-learnVemos algo como esto cuando ejecutamos el comando anterior:

Una vez que la instalación se complete con Conda, podremos usar el paquete en nuestros scripts de Python como:
importar sklearnComencemos a usar scikit-learn en nuestros scripts para desarrollar increíbles algoritmos de aprendizaje automático.
Importación de conjuntos de datos
Una de las cosas interesantes de scikit-learn es que viene precargado con conjuntos de datos de muestra con los que es fácil comenzar rápidamente. Los conjuntos de datos son los iris y digitos conjuntos de datos para la clasificación y el precios de la vivienda en boston conjunto de datos para técnicas de regresión. En esta sección, veremos cómo cargar y comenzar a usar el conjunto de datos de iris.
Para importar un conjunto de datos, primero tenemos que importar el módulo correcto y luego obtener la retención del conjunto de datos:
desde sklearn importar conjuntos de datosiris = conjuntos de datos.load_iris ()
dígitos = conjuntos de datos.load_digits ()
digitos.datos
Una vez que ejecutemos el fragmento de código anterior, veremos el siguiente resultado:

Toda la salida se elimina por brevedad. Este es el conjunto de datos que usaremos principalmente en esta lección, pero la mayoría de los conceptos se pueden aplicar a todos los conjuntos de datos en general.
Un dato curioso es saber que hay varios módulos presentes en el scikit ecosistema, uno de los cuales es aprender utilizado para algoritmos de aprendizaje automático. Consulte esta página para ver muchos otros módulos presentes.
Explorando el conjunto de datos
Ahora que hemos importado el conjunto de datos de dígitos proporcionado a nuestro script, deberíamos comenzar a recopilar información básica sobre el conjunto de datos y eso es lo que haremos aquí. Estas son las cosas básicas que debe explorar mientras busca información sobre un conjunto de datos:
- Los valores o etiquetas de destino
- El atributo de descripción
- Las claves disponibles en el conjunto de datos dado
Escribamos un breve fragmento de código para extraer la información anterior de nuestro conjunto de datos:
print ('Destino:', dígitos.objetivo)print ('Teclas:', dígitos.llaves())
print ('Descripción:', dígitos.DESCR)
Una vez que ejecutemos el fragmento de código anterior, veremos el siguiente resultado:
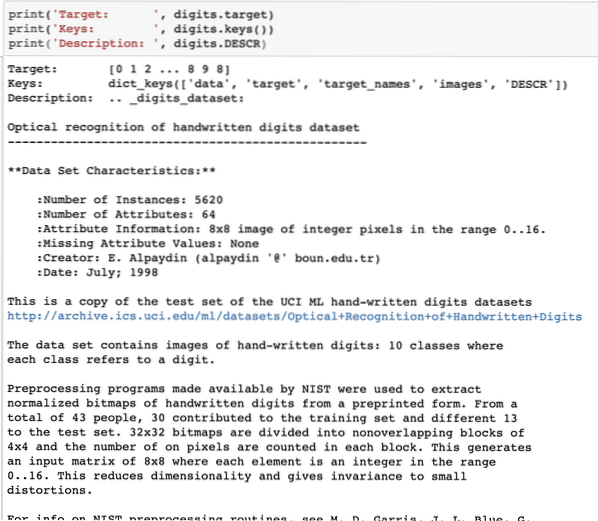
Tenga en cuenta que los dígitos variables no son sencillos. Cuando imprimimos el conjunto de datos de dígitos, en realidad contenía matrices numerosas. Veremos como podemos acceder a estos arreglos. Para esto, tome nota de las claves disponibles en la instancia de dígitos que imprimimos en el último fragmento de código.
Comenzaremos obteniendo la forma de los datos de la matriz, que son las filas y columnas que tiene la matriz. Para esto, primero necesitamos obtener los datos reales y luego obtener su forma:
digits_set = dígitos.datosimprimir (digits_set.forma)
Una vez que ejecutemos el fragmento de código anterior, veremos el siguiente resultado:

Esto significa que tenemos 1797 muestras presentes en nuestro conjunto de datos junto con 64 características de datos (o columnas). Además, también tenemos algunas etiquetas de destino que visualizaremos aquí con la ayuda de matplotlib. Aquí hay un fragmento de código que nos ayuda a hacerlo:
importar matplotlib.pyplot como plt# Fusionar las imágenes y las etiquetas de destino como una lista
images_and_labels = lista (zip (dígitos.imágenes, dígitos.objetivo))
para el índice, (imagen, etiqueta) en enumerate (images_and_labels [: 8]):
# inicializar una subtrama de 2X4 en la posición i + 1-th
plt.subtrama (2, 4, índice + 1)
# No es necesario trazar ningún eje
plt.eje ('apagado')
# Mostrar imágenes en todas las subtramas
plt.imshow (imagen, cmap = plt.cm.gray_r, interpolation = 'más cercano')
# Agrega un título a cada subtrama
plt.title ('Entrenamiento:' + str (etiqueta))
plt.show()
Una vez que ejecutemos el fragmento de código anterior, veremos el siguiente resultado:

Observe cómo comprimimos las dos matrices NumPy juntas antes de trazarlas en una cuadrícula de 4 por 2 sin información de ejes. Ahora, estamos seguros de la información que tenemos sobre el conjunto de datos con el que estamos trabajando.
Ahora que sabemos que tenemos 64 características de datos (que son muchas características por cierto), es un desafío visualizar los datos reales. Aunque tenemos una solución para esto.
Análisis de componentes principales (PCA)
Este no es un tutorial sobre PCA, pero déjanos dar una pequeña idea de lo que es. Como sabemos que para reducir la cantidad de características de un conjunto de datos, tenemos dos técnicas:
- Eliminación de características
- Extracción de características
Si bien la primera técnica enfrenta el problema de las características de datos perdidos incluso cuando podrían haber sido importantes, la segunda técnica no sufre el problema, ya que con la ayuda de PCA, construimos nuevas características de datos (menos en número) donde combinamos las variables de entrada de tal manera que podamos dejar de lado las variables "menos importantes" y al mismo tiempo conservar las partes más valiosas de todas las variables.
Como se esperaba, PCA nos ayuda a reducir la alta dimensionalidad de los datos que es un resultado directo de describir un objeto usando muchas características de datos. No solo los dígitos, sino muchos otros conjuntos de datos prácticos tienen un gran número de características que incluyen datos institucionales financieros, datos meteorológicos y económicos de una región, etc. Cuando realizamos PCA en el conjunto de datos de dígitos, nuestro objetivo será encontrar solo 2 características que tengan la mayoría de las características del conjunto de datos.
Escribamos un fragmento de código simple para aplicar PCA en el conjunto de datos de dígitos para obtener nuestro modelo lineal de solo 2 características:
de sklearn.PCA de importación de descomposiciónfeature_pca = PCA (n_components = 2)
datos_reducidos_ aleatorio = feature_pca.fit_transform (dígitos.datos)
model_pca = PCA (n_components = 2)
pca_datos_reducidos = pca_modelo.fit_transform (dígitos.datos)
reducido_data_pca.forma
imprimir (datos_reducidos_aleatorio)
imprimir (datos_reducidos_pca)
Una vez que ejecutemos el fragmento de código anterior, veremos el siguiente resultado:
[[-1.2594655 21.27488324][7.95762224-20.76873116]
[6.99192123 -9.95598191]
..
[10.8012644 -6.96019661]
[-4.87210598 12.42397516]
[-0.34441647 6.36562581]]
[[-1.25946526 21.27487934]
[7.95761543-20.76870705]
[6.99191947 -9.9559785]
..
[10.80128422 -6.96025542]
[-4.87210144 12.42396098]
[-0.3443928 6.36555416]]
En el código anterior, mencionamos que solo necesitamos 2 características para el conjunto de datos.
Ahora que tenemos un buen conocimiento sobre nuestro conjunto de datos, podemos decidir qué tipo de algoritmos de aprendizaje automático podemos aplicar en él. Conocer un conjunto de datos es importante porque así es como podemos decidir qué información se puede extraer de él y con qué algoritmos. También nos ayuda a probar la hipótesis que establecemos al predecir valores futuros.
Aplicar clústeres de k-medias
El algoritmo de agrupación en clústeres de k-means es uno de los algoritmos de agrupación en clúster más fáciles para el aprendizaje no supervisado. En este agrupamiento, tenemos un número aleatorio de grupos y clasificamos nuestros puntos de datos en uno de estos grupos. El algoritmo de k-medias encontrará el grupo más cercano para cada uno de los puntos de datos dados y asignará ese punto de datos a ese grupo.
Una vez que se realiza la agrupación, el centro del grupo se vuelve a calcular, los puntos de datos se asignan a nuevos grupos si hay algún cambio. Este proceso se repite hasta que los puntos de datos dejan de cambiar sus grupos para lograr la estabilidad.
Simplemente apliquemos este algoritmo sin ningún procesamiento previo de los datos. Para esta estrategia, el fragmento de código será bastante sencillo:
desde el clúster de importación de sklearnk = 3
k_means = cluster.KMedias (k)
# ajustar datos
k_means.encajar (dígitos.datos)
# resultados de impresión
imprimir (k_means.etiquetas _ [:: 10])
imprimir (dígitos.objetivo [:: 10])
Una vez que ejecutemos el fragmento de código anterior, veremos el siguiente resultado:
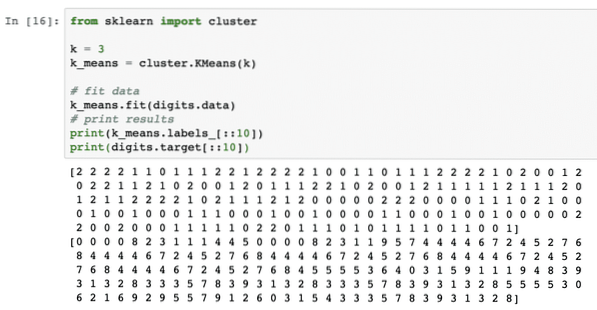
En la salida anterior, podemos ver que se proporcionan diferentes grupos a cada uno de los puntos de datos.
Conclusión
En esta lección, analizamos una excelente biblioteca de aprendizaje automático, scikit-learn. Descubrimos que hay muchos otros módulos disponibles en la familia scikit y aplicamos un algoritmo simple de k-medias en el conjunto de datos proporcionado. Hay muchos más algoritmos que se pueden aplicar en el conjunto de datos además del agrupamiento de k-medias que aplicamos en esta lección, lo alentamos a que lo haga y comparta sus resultados.
Comparta sus comentarios sobre la lección en Twitter con @sbmaggarwal y @LinuxHint.


