Pandas para análisis numérico
Pandas se desarrolló a partir de la necesidad de una forma eficiente de administrar datos financieros en Python. Pandas es una biblioteca que se puede importar a Python para ayudar a manipular y transformar datos numéricos. Wes McKinney inició el proyecto en 2008. Pandas ahora es administrado por un grupo de ingenieros y apoyado por la organización sin fines de lucro NUMFocus, que asegurará su crecimiento y desarrollo futuros. Esto significa que pandas será una biblioteca estable durante muchos años y se puede incluir en sus aplicaciones sin la preocupación de un proyecto pequeño.
Aunque pandas se desarrolló inicialmente para modelar datos financieros, sus estructuras de datos se pueden usar para manipular una variedad de datos numéricos. Pandas tiene una serie de estructuras de datos que están integradas y se pueden usar para modelar y manipular fácilmente datos numéricos. Este tutorial cubrirá los pandas Marco de datos estructura de datos en profundidad.
¿Qué es un DataFrame??
A Marco de datos es una de las estructuras de datos primarias en pandas y representa una colección de datos en 2-D. Hay muchos objetos análogos a este tipo de estructura de datos 2-D, algunos de los cuales incluyen la popular hoja de cálculo de Excel, una tabla de base de datos o una matriz 2-D que se encuentra en la mayoría de los lenguajes de programación. A continuación se muestra un ejemplo de Marco de datos en un formato gráfico. Representa un grupo de series de tiempo de precios de cierre de acciones por fecha.
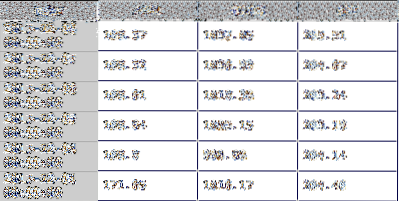
Este tutorial lo guiará a través de muchos de los métodos del marco de datos y usaré un modelo financiero del mundo real para demostrar estas funciones.
Importación de datos
Las clases de Pandas tienen algunos métodos integrados para ayudar con la importación de datos en una estructura de datos. A continuación se muestra un ejemplo de cómo importar datos a un panel pandas con el DataReader clase. Se puede utilizar para importar datos de varias fuentes de datos financieros gratuitas, incluidas Quandl, Yahoo Finance y Google. Para usar la biblioteca de pandas, debe agregarla como una importación en su código.
importar pandas como pdEl siguiente método iniciará el programa ejecutando el método de ejecución del tutorial.
if __name__ == "__main__":tutorial_run ()
La tutorial_run el método está debajo. Es el siguiente método que agregaré al código. La primera línea de este método define una lista de tickers de acciones. Esta variable se utilizará más adelante en el código como una lista de acciones para las que se solicitarán datos para completar el Marco de datos. La segunda línea de código llama al obtener datos método. Como veremos, el obtener datos El método toma tres parámetros como entrada. Pasaremos la lista de tickers de acciones, la fecha de inicio y la fecha de finalización de los datos que solicitaremos.
def tutorial_run ():#Tickers de stock a la fuente de Yahoo Finance
símbolos = ['SPY', 'AAPL', 'GOOG']
#obtener datos
df = get_data (símbolos, '2006-01-03', '2017-12-31')
A continuación definiremos el obtener datos método. Como mencioné anteriormente, se necesitan tres parámetros: una lista de símbolos, una fecha de inicio y finalización.
La primera línea de código define un panel de pandas instanciando un DataReader clase. La llamada a la DataReader la clase se conectará al servidor de Yahoo Finance y solicitará los valores diarios máximo, mínimo, cierre y cierre ajustado para cada una de las acciones en el simbolos lista. Estos datos son cargados en un objeto de panel por pandas.
A panel es una matriz 3-D y se puede considerar una "pila" de DataFrames. Cada Marco de datos en la pila contiene uno de los valores diarios para las existencias y los rangos de fechas solicitados. Por ejemplo, el siguiente Marco de datos, presentado anteriormente, es el precio de cierre Marco de datos de la solicitud. Cada tipo de precio (alto, bajo, cierre y cierre ajustado) tiene su propio Marco de datos en el panel resultante devuelto de la solicitud.
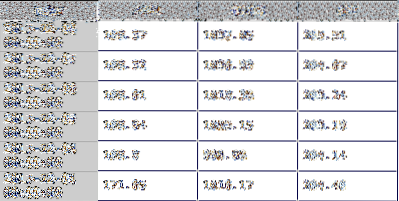
La segunda línea de código divide el panel en un solo Marco de datos y asigna los datos resultantes a df. Esta será mi variable para el Marco de datos que utilizo para el resto del tutorial. Mantiene valores de cierre diarios para las tres acciones para el rango de fechas especificado. El panel se corta especificando cuál de los paneles DataFrames te gustaria volver. En esta línea de código de ejemplo a continuación, es el 'Cerrar'.
Una vez que tenemos nuestro Marco de datos en su lugar, cubriré algunas de las funciones útiles en la biblioteca de pandas que nos permitirán manipular los datos en el Marco de datos objeto.
def get_data (símbolos, fecha_inicio, fecha_finalización):panel = datos.DataReader (símbolos, 'yahoo', fecha_inicio, fecha_finalización)
df = panel ['Cerrar']
imprimir (df.cabeza (5))
imprimir (df.cola (5))
volver df
Cabeza y cola
La tercera y cuarta línea de obtener datos imprimir el encabezado y la cola de la función del marco de datos. Encuentro esto más útil en la depuración y visualización de los datos, pero también se puede usar para seleccionar la primera o la última muestra de los datos en el Marco de datos. La función de cabeza y cola extrae la primera y la última fila de datos del Marco de datos. El parámetro entero entre paréntesis define el número de filas que se seleccionarán mediante el método.
.loc
La Marco de datos loc método corta el Marco de datos por índice. La siguiente línea de código corta el df Marco de datos por el índice 2017-12-12. He proporcionado una captura de pantalla de los resultados a continuación.
imprimir df.loc ["12/12/2017"]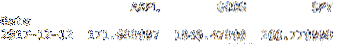
loc también se puede utilizar como un corte bidimensional. El primer parámetro es la fila y el segundo parámetro es la columna. El siguiente código devuelve un valor único que es igual al precio de cierre de Apple el 12/12/2014.
imprimir df.loc ["12/12/2017", "AAPL"]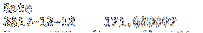
La loc El método se puede utilizar para dividir todas las filas de una columna o todas las columnas de una fila. La : El operador se usa para denotar todo. La siguiente línea de código selecciona todas las filas de la columna para los precios de cierre de Google.
imprimir df.loc [:, "GOOG"]
.Fillna
Es común, especialmente en conjuntos de datos financieros, tener valores de NaN en su Marco de datos. Pandas proporciona una función para completar estos valores con un valor numérico. Esto es útil si desea realizar algún tipo de cálculo en los datos que pueden estar sesgados o fallar debido a los valores de NaN.
La .Fillna El método sustituirá el valor especificado por cada valor de NaN en su conjunto de datos. La siguiente línea de código llenará todo el NaN en nuestro Marco de datos con un 0. Este valor predeterminado se puede cambiar por un valor que satisfaga la necesidad del conjunto de datos con el que está trabajando actualizando el parámetro que se pasa al método.
df.fillna (0)Normalización de datos
Cuando se utilizan algoritmos de aprendizaje automático o análisis financiero, a menudo es útil normalizar sus valores. El siguiente método es un cálculo eficiente para normalizar datos en pandas Marco de datos. Le animo a usar este método porque este código se ejecutará de manera más eficiente que otros métodos para normalizar y puede mostrar grandes aumentos de rendimiento en grandes conjuntos de datos.
.iloc es un método similar a .loc pero toma parámetros basados en la ubicación en lugar de los parámetros basados en etiquetas. Toma un índice basado en cero en lugar del nombre de columna del .loc ejemplo. El siguiente código de normalización es un ejemplo de algunos de los potentes cálculos matriciales que se pueden realizar. Me saltaré la lección de álgebra lineal, pero esencialmente esta línea de código dividirá toda la matriz o Marco de datos por el primer valor de cada serie de tiempo. Dependiendo de su conjunto de datos, es posible que desee una norma basada en mínimo, máximo o medio. Estas normas también se pueden calcular fácilmente utilizando el estilo basado en matrices que se muestra a continuación.
def normalizar_datos (df):return df / df.iloc [0 ,:]
Trazar datos
Cuando se trabaja con datos, a menudo es necesario representarlos gráficamente. El método de trazado le permite crear fácilmente un gráfico a partir de sus conjuntos de datos.
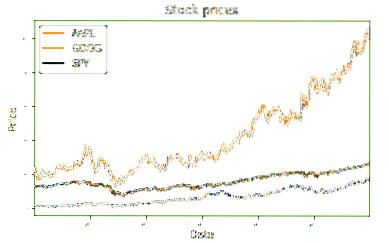
El método a continuación toma nuestro Marco de datos y lo traza en un gráfico lineal estándar. El método toma un Marco de datos y un título como sus parámetros. La primera línea de conjuntos de códigos hacha a una parcela de la DataFrame df. Establece el título y el tamaño de fuente del texto. Las siguientes dos líneas establecen las etiquetas para los ejes xey. La última línea de código llama al método show que imprime el gráfico en la consola. Proporcioné una captura de pantalla de los resultados del gráfico a continuación. Esto representa los precios de cierre normalizados para cada una de las acciones durante el período de tiempo seleccionado.
def plot_data (df, title = "Precios de las acciones"):ax = df.trama (título = título, tamaño de fuente = 2)
hacha.set_xlabel ("Fecha")
hacha.set_ylabel ("Precio")
gráfico.show()
Pandas es una biblioteca robusta de manipulación de datos. Se puede utilizar para diferentes tipos de datos y presenta un conjunto de métodos sucinto y eficiente para manipular su conjunto de datos. A continuación, proporcioné el código completo del tutorial para que pueda revisarlo y cambiarlo para satisfacer sus necesidades. Hay algunos otros métodos que lo ayudan con la manipulación de datos y lo animo a revisar los documentos de pandas publicados en las páginas de referencia a continuación. NumPy y MatPlotLib son otras dos bibliotecas que funcionan bien para la ciencia de datos y se pueden usar para mejorar el poder de la biblioteca de pandas.
Código completo
importar pandas como pddef plot_selected (df, columnas, índice_inicio, índice_final):
plot_data (df.ix [start_index: end_index, columnas])
def get_data (símbolos, fecha_inicio, fecha_finalización):
panel = datos.DataReader (símbolos, 'yahoo', fecha_inicio, fecha_finalización)
df = panel ['Cerrar']
imprimir (df.cabeza (5))
imprimir (df.cola (5))
imprimir df.loc ["12/12/2017"]
imprimir df.loc ["12/12/2017", "AAPL"]
imprimir df.loc [:, "GOOG"]
df.fillna (0)
volver df
def normalizar_datos (df):
return df / df.ix [0 ,:]
def plot_data (df, title = "Precios de las acciones"):
ax = df.trama (título = título, tamaño de fuente = 2)
hacha.set_xlabel ("Fecha")
hacha.set_ylabel ("Precio")
gráfico.show()
def tutorial_run ():
#Elegir símbolos
símbolos = ['SPY', 'AAPL', 'GOOG']
#obtener datos
df = get_data (símbolos, '2006-01-03', '2017-12-31')
plot_data (df)
if __name__ == "__main__":
tutorial_run ()
Referencias
Página de inicio de Pandas
Página de Wikipedia de Pandas
https: // en.wikipedia.org / wiki / Wes_McKinney
Página de inicio de NumFocus


