También hay una opción para guardar un diseño gráfico fuera de línea para que se puedan exportar fácilmente. Hay muchas otras características que facilitan el uso de la biblioteca:
- Guarde los gráficos para usarlos sin conexión como gráficos vectoriales que están altamente optimizados para imprimirlos y publicarlos
- Los gráficos exportados están en formato JSON y no en formato de imagen. Este JSON puede cargarse en otras herramientas de visualización como Tableau fácilmente o manipularse con Python o R
- Como los gráficos exportados son de naturaleza JSON, es prácticamente muy fácil incrustar estos gráficos en una aplicación web
- Plotly es una buena alternativa para Matplotlib para visualización
Para comenzar a utilizar el paquete Plotly, debemos registrarnos en una cuenta en el sitio web mencionado anteriormente para obtener un nombre de usuario y una clave API válidos con los que podamos comenzar a usar sus funcionalidades. Afortunadamente, hay disponible un plan de precios gratuito para Plotly con el que obtenemos suficientes funciones para hacer gráficos de calidad de producción.
Instalación de Plotly
Solo una nota antes de comenzar, puede usar un entorno virtual para esta lección que podemos realizar con el siguiente comando:
python -m virtualenv plotlyfuente numpy / bin / activar
Una vez que el entorno virtual está activo, puede instalar la biblioteca Plotly dentro del entorno virtual para que los ejemplos que creamos a continuación se puedan ejecutar:
pip instalar plotlyUsaremos Anaconda y Jupyter en esta lección. Si desea instalarlo en su máquina, consulte la lección que describe “Cómo instalar Anaconda Python en Ubuntu 18.04 LTS ”y comparta sus comentarios si tiene algún problema. Para instalar Plotly con Anaconda, use el siguiente comando en la terminal de Anaconda:
conda install -c plotly plotlyVemos algo como esto cuando ejecutamos el comando anterior:
Una vez que todos los paquetes necesarios están instalados y listos, podemos comenzar a usar la biblioteca Plotly con la siguiente declaración de importación:
importar tramaUna vez que haya creado una cuenta en Plotly, necesitará dos cosas: el nombre de usuario de la cuenta y una clave API. Solo puede haber una clave API que pertenezca a cada cuenta. Así que guárdelo en un lugar seguro como si lo perdiera, tendrá que regenerar la clave y todas las aplicaciones antiguas que usen la clave anterior dejarán de funcionar.
En todos los programas de Python que escriba, mencione las credenciales de la siguiente manera para comenzar a trabajar con Plotly:
tramadamente.herramientas.set_credentials_file (username = 'username', api_key = 'your-api-key')Comencemos con esta biblioteca ahora.
Introducción a Plotly
Utilizaremos las siguientes importaciones en nuestro programa:
importar pandas como pdimportar numpy como np
importar scipy como sp
importar trama.parcela como py
Hacemos uso de:
- Pandas para leer archivos CSV de manera efectiva
- NumPy para operaciones tabulares simples
- Scipy para cálculos científicos
- Plotly para visualización
Para algunos de los ejemplos, haremos uso de los propios conjuntos de datos de Plotly disponibles en Github. Finalmente, tenga en cuenta que también puede habilitar el modo fuera de línea para Plotly cuando necesite ejecutar scripts de Plotly sin una conexión de red:
importar pandas como pdimportar numpy como np
importar scipy como sp
importar trama
trama.desconectado.init_notebook_mode (conectado = Verdadero)
importar trama.fuera de línea como py
Puede ejecutar la siguiente declaración para probar la instalación de Plotly:
imprimir.__versión__)Vemos algo como esto cuando ejecutamos el comando anterior:

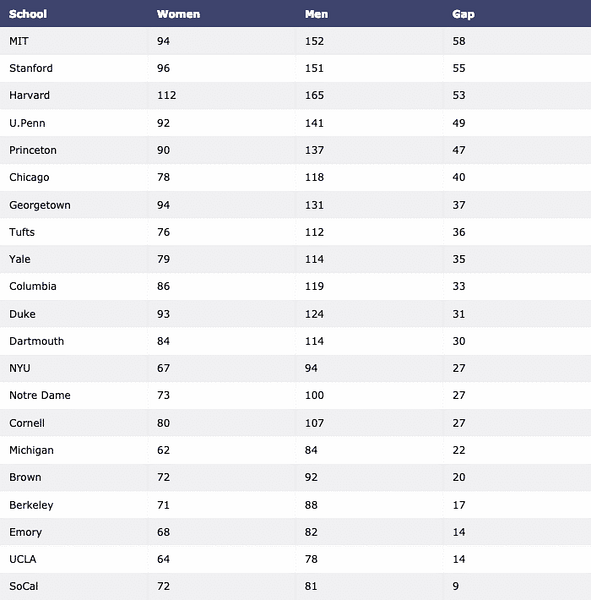
Finalmente descargaremos el conjunto de datos con Pandas y lo visualizaremos como una tabla:
importar trama.figure_factory como ffdf = pd.read_csv ("https: // raw.githubusercontent.com / plotly / datasets / master / school_
ganancias.csv ")
tabla = ff.create_table (df)
py.iplot (tabla, nombre de archivo = 'tabla')
Vemos algo como esto cuando ejecutamos el comando anterior:
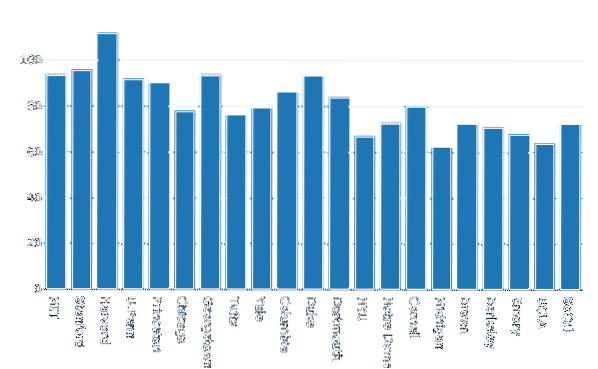
Ahora, construyamos un Gráfico de barras para visualizar los datos:
importar trama.graph_objs como irdata = [ir.Barra (x = gl.Escuela, y = df.Mujeres)]
py.iplot (datos, nombre de archivo = 'barra de mujeres')
Vemos algo como esto cuando ejecutamos el fragmento de código anterior:
Cuando vea el gráfico anterior con el cuaderno Jupyter, se le presentarán varias opciones de Zoom in / out en una sección particular del gráfico, Selección de cuadro y lazo y mucho más.
Gráficos de barras agrupadas
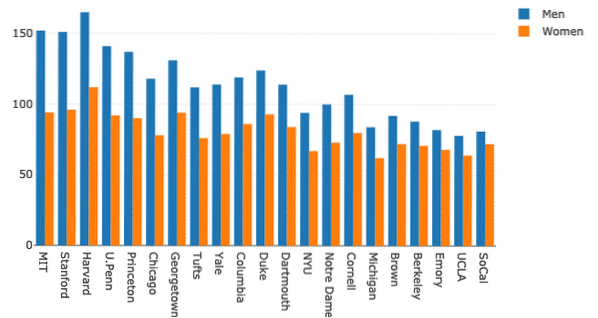
Se pueden agrupar varios gráficos de barras con fines de comparación muy fácilmente con Plotly. Usemos el mismo conjunto de datos para esto y mostremos la variación de la presencia de hombres y mujeres en las universidades:
mujeres = ir.Barra (x = gl.Escuela, y = df.Mujeres)hombres = ir.Barra (x = gl.Escuela, y = df.Hombres)
data = [hombres, mujeres]
diseño = ir.Diseño (barmode = "grupo")
fig = ir.Figura (datos = datos, diseño = diseño)
py.iplot (fig)
Vemos algo como esto cuando ejecutamos el fragmento de código anterior:

Aunque se ve bien, las etiquetas de la esquina superior derecha no son correctas! Vamos a corregirlos:
mujeres = ir.Barra (x = gl.Escuela, y = df.Mujeres, nombre = "Mujeres")hombres = ir.Barra (x = gl.Escuela, y = df.Hombres, nombre = "Hombres")
El gráfico parece mucho más descriptivo ahora:
Intentemos cambiar el modo de barra:
diseño = ir.Diseño (barmode = "relativo")fig = ir.Figura (datos = datos, diseño = diseño)
py.iplot (fig)
Vemos algo como esto cuando ejecutamos el fragmento de código anterior:
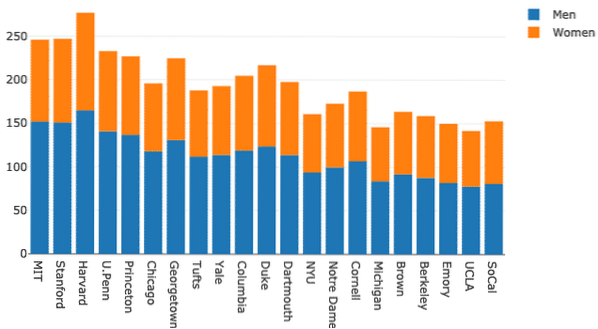
Gráficos circulares con Plotly
Ahora, intentaremos construir un gráfico circular con Plotly que establezca una diferencia básica entre el porcentaje de mujeres en todas las universidades. El nombre de las universidades serán las etiquetas y los números reales se utilizarán para calcular el porcentaje del total. Aquí está el fragmento de código para el mismo:
trace = ir.Pie (etiquetas = df.Escuela, valores = gl.Mujeres)py.iplot ([trace], filename = 'pie')
Vemos algo como esto cuando ejecutamos el fragmento de código anterior:
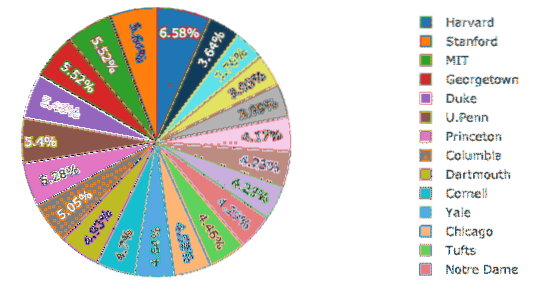
Lo bueno es que Plotly viene con muchas funciones de acercamiento y alejamiento y muchas otras herramientas para interactuar con el gráfico construido.
Visualización de datos de series temporales con Plotly
La visualización de datos de series de tiempo es una de las tareas más importantes que se presentan cuando eres un analista de datos o un ingeniero de datos.
En este ejemplo, usaremos un conjunto de datos separado en el mismo repositorio de GitHub, ya que los datos anteriores no involucraban ningún dato con sello de tiempo específicamente. Como aquí, trazaremos la variación de las acciones de mercado de Apple a lo largo del tiempo:
financiero = pd.read_csv ("https: // sin procesar.githubusercontent.com / plotly / datasets / master /finanzas-gráficos-manzana.csv ")
data = [ir.Dispersión (x = financiera.Fecha, y = financiera ['AAPL.Cerca'])]
py.iplot (datos)
Vemos algo como esto cuando ejecutamos el fragmento de código anterior:
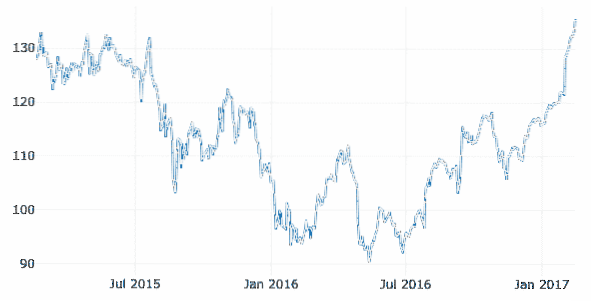
Una vez que pase el mouse sobre la línea de variación del gráfico, puede especificar detalles de puntos:

También podemos usar los botones de acercar y alejar para ver datos específicos de cada semana.
Gráfico OHLC
Se utiliza un gráfico OHLC (Open High Low close) para mostrar la variación de una entidad a lo largo de un período de tiempo. Esto es fácil de construir con PyPlot:
desde fecha y hora importar fecha y horaopen_data = [33.0, 35.3, 33.5, 33.0, 34.1]
high_data = [33.1, 36.3, 33.6, 33.2, 34.8]
low_data = [32.7, 32.7, 32.8, 32.6, 32.8]
close_data = [33.0, 32.9, 33.3, 33.1, 33.1]
fechas = [fecha y hora (año = 2013, mes = 10, día = 10),
fecha y hora (año = 2013, mes = 11, día = 10),
fecha y hora (año = 2013, mes = 12, día = 10),
fecha y hora (año = 2014, mes = 1, día = 10),
fecha y hora (año = 2014, mes = 2, día = 10)]
trace = ir.Ohlc (x = fechas,
open = open_data,
high = high_data,
low = low_data,
close = close_data)
datos = [rastreo]
py.iplot (datos)
Aquí, hemos proporcionado algunos puntos de datos de muestra que se pueden inferir de la siguiente manera:
- Los datos abiertos describen la tasa de acciones cuando se abrió el mercado
- Los datos altos describen la tasa de existencias más alta lograda durante un período de tiempo determinado
- Los datos bajos describen la tasa de existencias más baja lograda durante un período de tiempo determinado
- Los datos de cierre describen la tasa de cierre de existencias cuando se terminó un intervalo de tiempo determinado
Ahora, ejecutemos el fragmento de código que proporcionamos anteriormente. Vemos algo como esto cuando ejecutamos el fragmento de código anterior:
Esta es una excelente comparación de cómo establecer comparaciones de tiempo de una entidad con la suya propia y compararla con sus logros altos y bajos.
Conclusión
En esta lección, analizamos otra biblioteca de visualización, Plotly, que es una excelente alternativa a Matplotlib en aplicaciones de grado de producción que se exponen como aplicaciones web, Plotly es una biblioteca muy dinámica y rica en funciones para usar con fines de producción, por lo que definitivamente es una habilidad que debemos tener en nuestro haber.
Encuentre todo el código fuente utilizado en esta lección en Github. Comparta sus comentarios sobre la lección en Twitter con @sbmaggarwal y @LinuxHint.


