Comencemos con una definición ingenua de 'apatridia' y luego avancemos lentamente hacia una visión más rigurosa y del mundo real.
Una aplicación sin estado es aquella que no depende de un almacenamiento persistente. De lo único que es responsable su clúster es del código y otro contenido estático que se aloja en él. Eso es todo, sin cambios en las bases de datos, sin escrituras y sin archivos sobrantes cuando se elimina el pod.
Una aplicación con estado, por otro lado, tiene varios otros parámetros que se supone que debe cuidar en el clúster. Existen bases de datos dinámicas que, incluso cuando la aplicación está desconectada o eliminada, persisten en el disco. En un sistema distribuido, como Kubernetes, esto plantea varios problemas. Los veremos en detalle, pero primero aclaremos algunos conceptos erróneos.
Los servicios sin estado no son en realidad 'apátridas'
¿Qué significa cuando decimos el estado de un sistema?? Bueno, consideremos el siguiente ejemplo simple de una puerta automática.
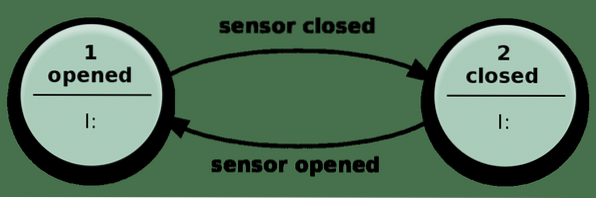
La puerta se abre cuando el sensor detecta que alguien se acerca y se cierra una vez que el sensor no recibe ninguna entrada relevante.
En la práctica, su aplicación sin estado es similar a este mecanismo anterior. Puede tener muchos más estados que solo cerrado o abierto, y muchos tipos diferentes de entrada, lo que lo hace más complejo pero esencialmente el mismo.
Puede resolver problemas complicados con solo recibir una entrada y realizar acciones que dependen tanto de la entrada como del 'estado' en el que se encuentra. El número de estados posibles está predefinido.
Entonces, la apatridia es un nombre inapropiado.
Las aplicaciones sin estado, en la práctica, también pueden hacer un poco de trampa al guardar detalles sobre, por ejemplo, las sesiones del cliente en el propio cliente (las cookies HTTP son un gran ejemplo) y aún tener una buena ausencia de estado que las haría funcionar sin problemas en el clúster.
Por ejemplo, los detalles de la sesión de un cliente, como qué productos se guardaron en el carrito y no se retiraron, pueden almacenarse en el cliente y la próxima vez que comience una sesión, estos detalles relevantes también se recordarán.
En un clúster de Kubernetes, una aplicación sin estado no tiene almacenamiento persistente ni volumen asociado. Desde la perspectiva de las operaciones, esta es una gran noticia. Diferentes pods en todo el clúster pueden funcionar de forma independiente con varias solicitudes que les llegan simultáneamente. Si algo sale mal, puede reiniciar la aplicación y volverá al estado inicial con poco tiempo de inactividad.
Servicios con estado y el teorema de CAP
Los servicios con estado, por otro lado, tendrán que preocuparse por muchos casos extremos y problemas extraños. Un pod está acompañado con al menos un volumen y si los datos en ese volumen están dañados, eso persiste incluso si se reinicia todo el clúster.
Por ejemplo, si está ejecutando una base de datos en un clúster de Kubernetes, todos los pods deben tener un volumen local para almacenar la base de datos. Todos los datos deben estar perfectamente sincronizados.
Entonces, si alguien modifica una entrada a la base de datos, y eso se hizo en el pod A, y aparece una solicitud de lectura en el pod B para ver esos datos modificados, entonces el pod B debe mostrar esos datos más recientes o darle un mensaje de error. Esto se conoce como consistencia.
Consistencia, en el contexto de un clúster de Kubernetes, significa cada lectura recibe la escritura más reciente o un mensaje de error.
Pero esto corta en contra disponibilidad, una de las razones más importantes para tener un sistema distribuido. La disponibilidad implica que su aplicación funciona lo más cerca posible de la perfección, las 24 horas del día, con el menor error posible.
Se puede argumentar que puede evitar todo esto si solo tiene una base de datos centralizada que es responsable de manejar todas las necesidades de almacenamiento persistentes. Ahora volvemos a tener un solo punto de falla, que es otro problema que se supone que los clústeres de Kubernetes deben resolver en primer lugar.
Necesita tener una forma descentralizada de almacenar datos persistentes en un clúster. Comúnmente conocido como partición de red. Además, su clúster debe poder sobrevivir a la falla de los nodos que ejecutan la aplicación con estado. Esto se conoce como tolerancia de partición.
Cualquier servicio (o aplicación) con estado que se ejecute en un clúster de Kubernetes debe tener un equilibrio entre estos tres parámetros. En la industria, se conoce como el teorema de CAP, donde las compensaciones entre consistencia y disponibilidad se consideran en presencia de particiones de red.
Referencias adicionales
Para obtener más información sobre el teorema de CAP, es posible que desee ver esta excelente charla de Bryan Cantrill, quien analiza mucho más de cerca la ejecución de sistemas distribuidos en producción.


