Por ejemplo, si desea obtener actualizaciones periódicas sobre sus productos favoritos para ofertas de descuento o si desea automatizar el proceso de descarga de episodios de su temporada favorita uno por uno, y el sitio web no tiene ninguna API, entonces la única opción. lo que te queda es web scraping.El web scraping puede ser ilegal en algunos sitios web, dependiendo de si un sitio web lo permite o no. Los sitios web utilizan "robots.txt ”para definir explícitamente las URL que no pueden eliminarse. Puede comprobar si el sitio web lo permite o no agregando "robots.txt ”con el nombre de dominio del sitio web. Por ejemplo, https: // www.Google.com / robots.TXT
En este artículo, usaremos Python para raspar porque es muy fácil de configurar y usar. Tiene muchas bibliotecas integradas y de terceros que se pueden usar para raspar y organizar datos. Usaremos dos bibliotecas de Python "urllib" para buscar la página web y "BeautifulSoup" para analizar la página web y aplicar operaciones de programación.
Cómo funciona Web Scraping?
Enviamos una solicitud a la página web, desde donde desea raspar los datos. El sitio web responderá a la solicitud con contenido HTML de la página. Luego, podemos analizar esta página web en BeautifulSoup para su posterior procesamiento. Para obtener la página web, usaremos la biblioteca "urllib" en Python.
Urllib descargará el contenido de la página web en HTML. No podemos aplicar operaciones de cadena a esta página web HTML para la extracción de contenido y su posterior procesamiento. Usaremos una biblioteca de Python "BeautifulSoup" que analizará el contenido y extraerá los datos interesantes.
Extracción de artículos de Linuxhint.com
Ahora que tenemos una idea de cómo funciona el web scraping, practiquemos. Intentaremos extraer títulos de artículos y enlaces de Linuxhint.com. Así que abre https: // linuxhint.com / en su navegador.
Ahora presione CRTL + U para ver el código fuente HTML de la página web.
Copie el código fuente y vaya a https: // htmlformatter.com / para embellecer el código. Después de embellecer el código, es fácil inspeccionar el código y encontrar información interesante.
Ahora, vuelva a copiar el código formateado y péguelo en su editor de texto favorito como atom, texto sublime, etc. Ahora rasparemos la información interesante usando Python. Escriba lo siguiente
// Instala una hermosa biblioteca de sopas, viene urllibpreinstalado en Python
ubuntu @ ubuntu: ~ $ sudo pip3 instalar bs4
ubuntu @ ubuntu: ~ $ python3
Python 3.7.3 (predeterminado, 7 de octubre de 2019, 12:56:13)
[CCG 8.3.0] en linux
Escriba "ayuda", "derechos de autor", "créditos" o "licencia" para obtener más información.
// Importar urllib>>> importar urllib.pedido
// Importar BeautifulSoup
>>> de bs4 importar BeautifulSoup
// Ingrese la URL que desea buscar
>>> my_url = 'https: // linuxhint.com / '
// Solicite la página web URL usando el comando urlopen
>>> cliente = urllib.pedido.urlopen (mi_url)
// Almacenar la página web HTML en la variable "html_page"
>>> html_page = cliente.leer()
// Cierre la conexión URL después de obtener la página web
>>> cliente.cerca()
// analizar la página web HTML a BeautifulSoup para raspar
>>> page_soup = BeautifulSoup (html_page, "html.analizador ")
Ahora echemos un vistazo al código fuente HTML que acabamos de copiar y pegar para encontrar cosas de nuestro interés.
Puede ver que el primer artículo que aparece en Linuxhint.com se llama "74 ejemplos de operadores Bash", busque esto en el código fuente. Está encerrado entre etiquetas de encabezado y su código es
title = "74 Ejemplos de operadores Bash"> 74 Operadores Bash
Ejemplos de
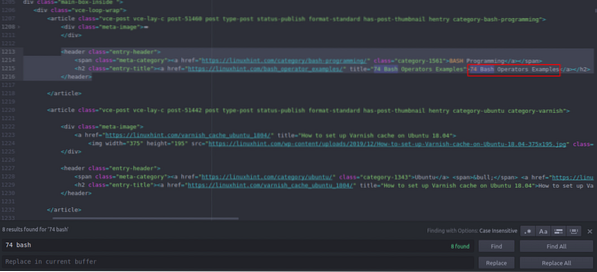
El mismo código se repite una y otra vez con el cambio de solo los títulos y enlaces de los artículos. El siguiente artículo tiene el siguiente código HTML
title = "Cómo configurar la caché de Varnish en Ubuntu 18.04 ">
Cómo configurar la caché de Varnish en Ubuntu 18.04
Puede ver que todos los artículos, incluidos estos dos, están incluidos en el mismo "
"Etiqueta y usa la misma clase" título de entrada ". Podemos usar la función "findAll" en la biblioteca Beautiful Soup para buscar y enumerar todos los ""Que tiene la clase" título de entrada ". Escriba lo siguiente en su consola de Python // Este comando encontrará todo ""Elementos de etiqueta que tienen una clase denominada
"Título de la entrada". La salida se almacenará en una matriz.
>>> artículos = page_soup.findAll ("h2" ,
"class": "entry-title")
// El número de artículos encontrados en la página principal de Linuxhint.com
>>> len (artículos)
102
// Primero extraído ""Elemento de etiqueta que contiene el nombre del artículo y el enlace
>>> artículos [0]
title = "74 Ejemplos de operadores Bash">
74 Ejemplos de operadores de Bash
// Segundo extraído ""Elemento de etiqueta que contiene el nombre del artículo y el enlace
>>> artículos [1]
title = "Cómo configurar la caché de Varnish en Ubuntu 18.04 ">
Cómo configurar la caché de Varnish en Ubuntu 18.04
// Mostrar solo texto en etiquetas HTML usando la función de texto
>>> artículos [1].texto
'Cómo configurar la caché de Varnish en Ubuntu 18.04 '
"Elementos de etiqueta que tienen una clase denominada
"Título de la entrada". La salida se almacenará en una matriz.
>>> artículos = page_soup.findAll ("h2" ,
"class": "entry-title")
// El número de artículos encontrados en la página principal de Linuxhint.com
>>> len (artículos)
102
// Primero extraído ""Elemento de etiqueta que contiene el nombre del artículo y el enlace
>>> artículos [0]
title = "74 Ejemplos de operadores Bash">
74 Ejemplos de operadores de Bash
// Segundo extraído ""Elemento de etiqueta que contiene el nombre del artículo y el enlace
>>> artículos [1]
title = "Cómo configurar la caché de Varnish en Ubuntu 18.04 ">
Cómo configurar la caché de Varnish en Ubuntu 18.04
// Mostrar solo texto en etiquetas HTML usando la función de texto
>>> artículos [1].texto
'Cómo configurar la caché de Varnish en Ubuntu 18.04 '
>>> artículos [0]
title = "74 Ejemplos de operadores Bash">
74 Ejemplos de operadores de Bash
// Segundo extraído "
"Elemento de etiqueta que contiene el nombre del artículo y el enlace
>>> artículos [1]
title = "Cómo configurar la caché de Varnish en Ubuntu 18.04 ">
Cómo configurar la caché de Varnish en Ubuntu 18.04
// Mostrar solo texto en etiquetas HTML usando la función de texto
>>> artículos [1].texto
'Cómo configurar la caché de Varnish en Ubuntu 18.04 '
title = "Cómo configurar la caché de Varnish en Ubuntu 18.04 ">
Cómo configurar la caché de Varnish en Ubuntu 18.04
Ahora que tenemos una lista de los 102 HTML "
"Elementos de etiqueta que contienen el enlace y el título del artículo. Podemos extraer tanto los enlaces como los títulos de los artículos. Para extraer enlaces de "", Podemos usar el siguiente código // El siguiente código extraerá el enlace de primero elemento de etiqueta
>>> para enlace en artículos [0].find_all ('a', href = True):
... imprimir (enlace ['href'])
..
https: // linuxhint.com / bash_operator_examples /
Ahora podemos escribir un bucle for que recorra cada "
"Elemento de etiqueta en la lista" artículos "y extraiga el enlace y el título del artículo. >>> para i en el rango (0,10):
… Imprimir (artículos [i].texto)
... para el enlace en los artículos [i].find_all ('a', href = True):
... imprimir (enlace ['href'] + "\ n")
..
74 Ejemplos de operadores de Bash
https: // linuxhint.com / bash_operator_examples /
Cómo configurar la caché de Varnish en Ubuntu 18.04
https: // linuxhint.com / varnish_cache_ubuntu_1804 /
PineTime: un reloj inteligente compatible con Linux
https: // linuxhint.com / pinetime_linux_smartwatch /
Las 10 mejores computadoras portátiles Linux baratas para comprar con un presupuesto
https: // linuxhint.com / best_cheap_linux_laptops /
Juegos HD remasterizados para Linux que nunca tuvieron una versión de Linux ..
https: // linuxhint.com / hd_remastered_games_linux /
Aplicaciones de grabación de pantalla de 60 FPS para Linux
https: // linuxhint.com / 60_fps_screen_recording_apps_linux /
74 Ejemplos de operadores de Bash
https: // linuxhint.com / bash_operator_examples /
... recortar ..
Del mismo modo, guarda estos resultados en un archivo JSON o CSV.
Conclusión
Sus tareas diarias no son solo la administración de archivos o la ejecución de comandos del sistema. También puede automatizar tareas relacionadas con la web, como la automatización de la descarga de archivos o la extracción de datos, raspando la web en Python. Este artículo se limitó a una simple extracción de datos, pero puede realizar una gran automatización de tareas usando "urllib" y "BeautifulSoup".
>>> para enlace en artículos [0].find_all ('a', href = True):
... imprimir (enlace ['href'])
..
https: // linuxhint.com / bash_operator_examples /
… Imprimir (artículos [i].texto)
... para el enlace en los artículos [i].find_all ('a', href = True):
... imprimir (enlace ['href'] + "\ n")
..
74 Ejemplos de operadores de Bash
https: // linuxhint.com / bash_operator_examples /
Cómo configurar la caché de Varnish en Ubuntu 18.04
https: // linuxhint.com / varnish_cache_ubuntu_1804 /
PineTime: un reloj inteligente compatible con Linux
https: // linuxhint.com / pinetime_linux_smartwatch /
Las 10 mejores computadoras portátiles Linux baratas para comprar con un presupuesto
https: // linuxhint.com / best_cheap_linux_laptops /
Juegos HD remasterizados para Linux que nunca tuvieron una versión de Linux ..
https: // linuxhint.com / hd_remastered_games_linux /
Aplicaciones de grabación de pantalla de 60 FPS para Linux
https: // linuxhint.com / 60_fps_screen_recording_apps_linux /
74 Ejemplos de operadores de Bash
https: // linuxhint.com / bash_operator_examples /
... recortar ..


